Metadata
| source | https://newsletter.pragmaticengineer.com/p/what-is-inference-engineering |
|---|---|
| created | 2026-04-01 |
| by | openai:gpt-5.4 |
추론 엔지니어링란 무엇인가? 심층 분석
많은 엔지니어가 매일 추론을 사용하지만, 추론 엔지니어링은 다소 생소하며 흥미로운 과제가 풍부한 분야입니다. 신간 『인퍼런스 엔지니어링 (Inference Engineering)』의 저자 필립 킬리 (Philip Kiely) 가 설명합니다.
2 년 전, 우리는 ChatGPT 팀 으로부터 LLM 이 어떻게 작동하는지 에 대한 개요를 배웠습니다. 그리고 오늘날 거의 모든 소프트웨어 엔지니어가 일상 업무에서 대규모 언어 모델 (LLM) 을 사용하고 있습니다. LLM 사용에서 가장 가시적인 부분은 추론 (inference)입니다. 기존 모델이 입력 (프롬프트) 을 받아 한 번에 하나의 토큰씩 출력을 생성하는 과정이기 때문입니다.
2026 년 현재 기술 산업 전반에 AI 모델과 AI 에이전트가 곳곳에 퍼져 있다는 것은, 곧 추론도 그렇다는 것을 의미합니다. 그리고 오픈 LLM 모델의 성능이 향상됨에 따라 추론 엔지니어링도 점점 더 보편화되고 있습니다. 폐쇄형 모델의 경우 추론 엔지니어링은 모델을 구축한 AI 엔지니어들만 수행합니다. 전 세계적으로 그 수는 기껏해야 수천 명 수준입니다. 반면, 기술 기업들이 도입하는 오픈 모델의 경우 더 나은 추론 성능을 발휘하도록 미세 조정할 수 있습니다.
예를 들어, 커서 (Cursor) 는 오픈 소스인 키미 (Kimi) 2.5 모델을 기반으로 새로운 Composer 2.0 모델을 구축했으며, 다양한 추론 엔지니어링 기법을 활용해 이를 한층 더 빠르게 만드는 데 성공했습니다.
따라서 이러한 산업 전반의 보급과 우수한 기술 성능에 대한 필요성을 고려할 때, 소프트웨어 엔지니어로서 추론 엔지니어링이 정확히 무엇인지, 그리고 알아두면 유용한 흥미로운 접근법에는 어떤 것이 있는지 이해할 가치가 있습니다. 이에 대한 답을 얻기 위해 추론 전문 스타트업인 베이스튼 (Baseten) 에서 4 년간 근무해 온 소프트웨어 엔지니어 필립 킬리 를 찾아보았습니다. 필립은 그간 쌓은 귀중한 경험을 바탕으로 이 주제를 깊이 있게 다룬 훌륭한 책, 바로 『인퍼런스 엔지니어링 (Inference Engineering)』을 집필했습니다.
 제 개인 소장용 『인퍼런스 엔지니어링』사본
제 개인 소장용 『인퍼런스 엔지니어링』사본
이번 호에서는 다음 내용을 다룹니다.
- 배경: 추론이 그토록 중요한 이유는? 더 유능하고 광범위하며 오픈된 모델들이 추론 엔지니어링에 대한 수요를 주도하고 있습니다.
- 추론이란? 모델 훈련 이후의 단계로, 배치 처리, 캐싱, 양자화 등 새로운 엔지니어링 과제를 도입하는 추론 계층에 대해 다룹니다.
- 언제 추론 엔지니어링이 필요한가? 제품과 사용량이 확장되고, 현재 시중의 기성 솔루션으로는 충족할 수 없는 제품 요구사항이 있을 때 투자가 가치가 있습니다.
- 추론에는 어떤 하드웨어가 사용되는가? 데이터센터용 GPU 가 가장 일반적이며, 사내 구축형 공기 차단 (air-gapped) GPU 도 사용됩니다.
- 추론에는 어떤 소프트웨어가 사용되는가? NVIDIA 의 CUDA 와 다이나모 (Dynamo), 그리고 PyTorch, vLLM 과 같은 하드웨어 중립적 프로젝트들이 널리 사용되며 인기가 높아지고 있습니다.
- 추론에는 어떤 인프라가 필요한가? 자동 확장은 기본 요구사항입니다. 클러스터 내 자동 확장에는 쿠버네티스 (Kubernetes) 가 인기가 높으며, 대규모 사용 사례의 경우 멀티 클라우드 추론이 필요할 수 있습니다.
- 추론을 빠르게 하는 5 가지 접근법. 양자화 (모델 가중치의 수치 정밀도 축소), 추론적 디코딩 (남는 연산 능력을 활용해 "초안 토큰" 생성), 캐싱, 병렬화 (텐서 병렬화 및 전문가 병렬화), 그리고 분리 (사전 채움 (prefill) 과 디코드 단계를 분리하여 동일한 GPU 가 아닌 별도의 워커에서 실행) 등입니다.
이 심층 분석에서는 추론 엔지니어들에게는 일상이지만, 해당 도메인에 익숙하지 않은 분들에게는 낯설 수 있는 몇 가지 약어와 개념을 사용합니다.
- CUDA: 컴퓨트 통합 디바이스 아키텍처 (Compute Unified Device Architecture). LLM 관련 사용 사례를 포함한 고성능 컴퓨팅을 위해 NVIDIA GPU 를 프로그래밍하기 위한 NVIDIA 사의 독점 API 입니다.
- TTFT (Time To First Token): 첫 번째 토큰 생성 시간. "프롬프트 처리 시간"으로 생각하면 됩니다. 이 지표는 모델과 생성형 AI 시스템의 체감 응답 속도를 결정합니다.
- TPS (Tokens Per Second): 초당 토큰 수. 모델의 "타이핑 속도"와 유사합니다.
- ITL (Intertoken Latency): 토큰 간 지연 시간. 하나의 토큰을 생성한 시점부터 다음 토큰을 생성할 때까지의 시간입니다.
- KV 캐시 (Key-Value Cache): 어텐션 알고리즘의 캐시된 결과로, 추론 속도를 높이기 위해 요청 간에 재사용됩니다.
- ChatGPT 확장 심층 분석 에서 KV 캐시에 대한 자세한 내용을 다뤘습니다.
- Prefill(사전 채움) / Decode(디코드): 추론의 두 단계입니다. Prefill 은 모델이 전체 입력을 받아 토큰을 처리하고 KV 캐시를 출력하는 단계입니다. Decode 는 모델이 한 번에 하나의 토큰을 생성하는 단계입니다.
- MoE (Mixture of Experts): 전문가 혼합. 모델이 훨씬 적은 연산량으로 사전 훈련될 수 있게 해주는 아키텍처입니다. 이 접근법에 대한 자세한 내용을 참고하세요.
아래는 필립의 책 『인퍼런스 엔지니어링 (Inference Engineering)』에서 발췌한 추론에 대한 소개입니다. 이 책은 전자책 (e-book) 으로 무료 다운로드할 수 있습니다. 단행본은 현재 매진되었지만, 필립이 최대한 빠르게 추가 인쇄 중입니다.
언제나 그렇듯 제 추천 도서는 무보수이며, 이 글의 링크 중 어떤 것도 제휴 링크가 아님을 밝힙니다. 자세한 내용은 제 윤리 성명서를 참조하십시오.
그럼 이제 필립에게 바통을 넘기겠습니다.
1. 배경: 추론이 그토록 중요한 이유는?
추론은 AI 산업에서 가장 가치 있는 분야이지만, 추론 엔지니어링은 여전히 초기 단계에 있습니다. 추론 엔지니어들은 프로덕션 환경에서 생성형 AI 모델을 더 빠르고, 저렴하며, 안정적으로 서빙하기 위해 CUDA 부터 쿠버네티스 (Kubernetes) 에 이르기까지 스택 전 분야에서 활동합니다.
2022 년 말 ChatGPT 가 출시되었을 때, 전 세계에 추론 엔지니어는 기껏해야 수백 명 정도였으며, 스스로를 그렇게 부르지도 않았습니다. 이 전문가들은 대개 OpenAI, 미드저니 (Midjourney), 앤트로픽 (Anthropic) 과 같은 최전선 연구소나, 구글과 NVIDIA 같은 빅테크 기업에서 근무했습니다. 당시만 해도 AI 산업의 미래는 이럴 것이라 여겨졌습니다. 생성형 AI 모델 훈련이 워낙 어렵고 비싸서 단 몇몇 기업만이 폐쇄형 모델을 개발하고, 이에 따라 프로덕션 서빙을 위한 추론 엔지니어링이 필요할 것이라는 전망였습니다. 그 대체 미래에서 나머지 세상은 API 를 통해 AI 를 소비하고, 토큰 단위로 지능을 임대하는 단순 소비자에 머무를 뿐이었습니다.
3 년이 지난 지금, 생성형 AI 모델 훈련은 역시나 어렵고 비싸지만, 단 몇몇 기업만 참여할 만큼 제한적이지는 않은 것으로 드러났습니다. 대신, 허깅페이스 (Hugging Face)(일명 "AI 용 GitHub")에만 200 만 개 이상이 등록되는 등 오픈 모델이 폭발적으로 증가했습니다. 이로 인해 오늘날 모든 엔지니어가 자체 지능을 배포하여 AI 제품을 구동할 수 있게 되었습니다.
미국의 OpenAI 와 NVIDIA 네모트론 (Nemotron), 유럽의 미스트랄 AI(Mistral AI) 와 블랙 포리스트 연구소 (Black Forest Labs), 중국의 알리바바 Qwen, 딥시크 (DeepSeek) AI, Z AI, 문샷 (Moonshot) AI 에 이르기까지 전 세계 연구소들이 모든 양태 (modality) 의 오픈 모델을 정기적으로 출시하고 있습니다.
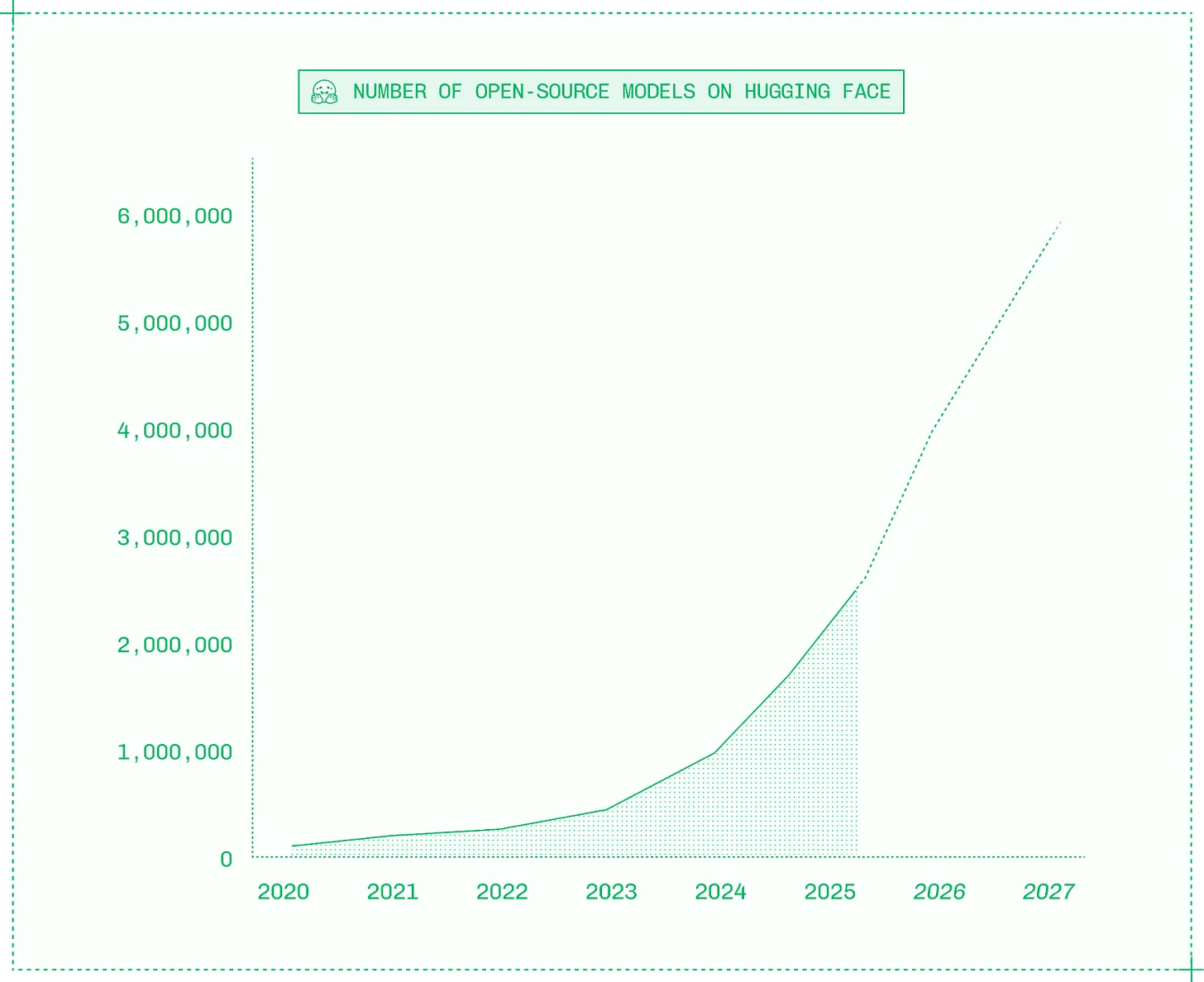 5 년 전보다 25 배 늘어난 200 만 개 이상의 허깅페이스 오픈 모델
5 년 전보다 25 배 늘어난 200 만 개 이상의 허깅페이스 오픈 모델
폐쇄형 모델이 더 똑똑해지고 저렴해지고 있음에도 불구하고, 가중치 (weights) 의 공개 여부에 따라 구별되는 오픈 모델로의 이동은 가속화되고 있습니다.
- 폐쇄형 모델 (Closed model): GPT-5 나 클로드 소네 (Claude Sonnet) 처처럼 가중치가 대중에게 공개되지 않은 독점 모델입니다.
- 오픈 모델 (Open model): 라마 (Llama) 나 딥시크 (DeepSeek) 처럼 가중치가 공개되어 있으며, 대개 MIT 라이선스 또는 이와 유사한 관대한 라이선스로 배포되는 모델입니다. (일부 모델은 상업적 사용을 제한하므로 라이선스 조항을 반드시 재확인해야 합니다.)
2024 년 12 월 이전까지는 폐쇄형 모델과 오픈 모델 간에 지능 수준에서 의미 있는 격차가 있었지만, 딥시크 V3 와 R1 이 출시되면서 그 격차는 사라졌습니다. (게르겔리의 코멘트: 과거에 딥시크의 출시가 AI 산업에 어떤 충격을 주었는지 다룬 바 있습니다.)
오늘날 새로운 폐쇄형 모델이 나오면 몇 달, 길어야 몇 주 안에 오픈 모델이 그 수준에 도달하며, 때로는 키미 K2 씽킹 (Kimi K2 Thinking) 과 같은 오픈 모델이 짧은 기간 동안 폐쇄형 모델의 능력을 능가하기도 합니다. 오픈 모델들이 벤치마크에서 폐쇄형 모델을 부지런히 따라잡고 있다는 사실에도 불구하고, 이들은 AI 제품 구축자들에게 공식을 바꾸는 계기가 됩니다. 두 유형 모두 발전함에 따라 폐쇄형과 오픈 모델은 능력의 임계점을 넘어섭니다.
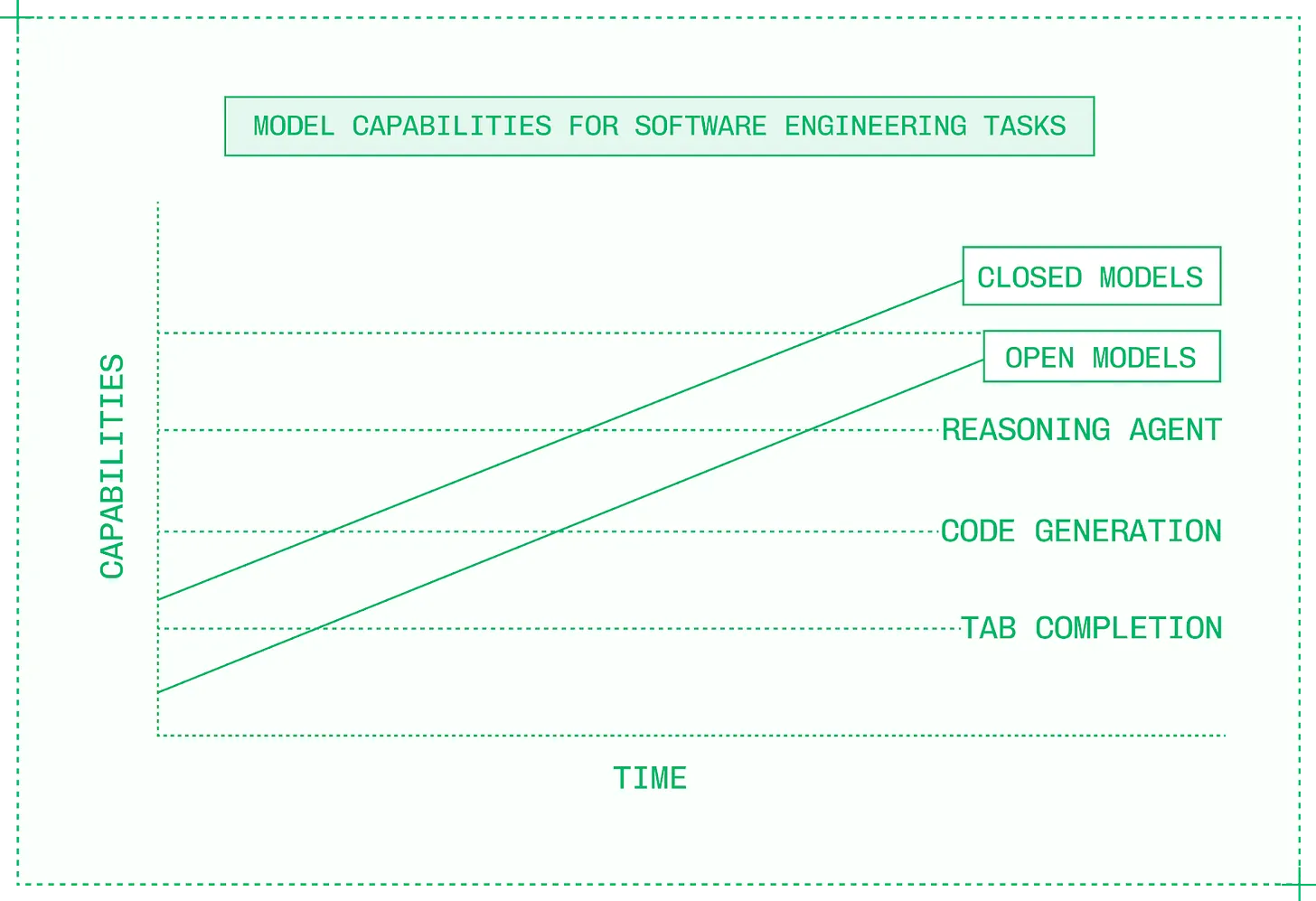 급속히 발전하는 오픈 및 폐쇄형 모델로 새로운 제품 구현이 가능해짐
급속히 발전하는 오픈 및 폐쇄형 모델로 새로운 제품 구현이 가능해짐
2022 년에는 오늘날 산업을 정의하는 종류의 AI 네이티브 제품을 만드는 것은 불가능했습니다. 그러나 시간이 지나 폐쇄형 모델이 더 똑똑해지면서 고객 서비스 음성 에이전트나 AI 기반 IDE 와 같은 새로운 카테고리가 가능해졌습니다. 초기 모델들은 느리고 비싸며 신뢰할 수 없었지만, 그 잠재력은 충분했고 AI 엔지니어들은 이를 바탕으로 회사를 설립하기 시작했습니다. 오픈 모델들이 동일한 능력 임계점을 넘어서자, 이들은 폐쇄형 모델을 대체하기 위해 오픈 모델을 사용하기 시작했습니다. 많은 이들이 특정 제품과 도메인에서 폐쇄형 모델의 품질을 더 빠르게 추월하거나 심지어 능가하기 위해 오픈 모델을 파인튜닝하기 시작했습니다.
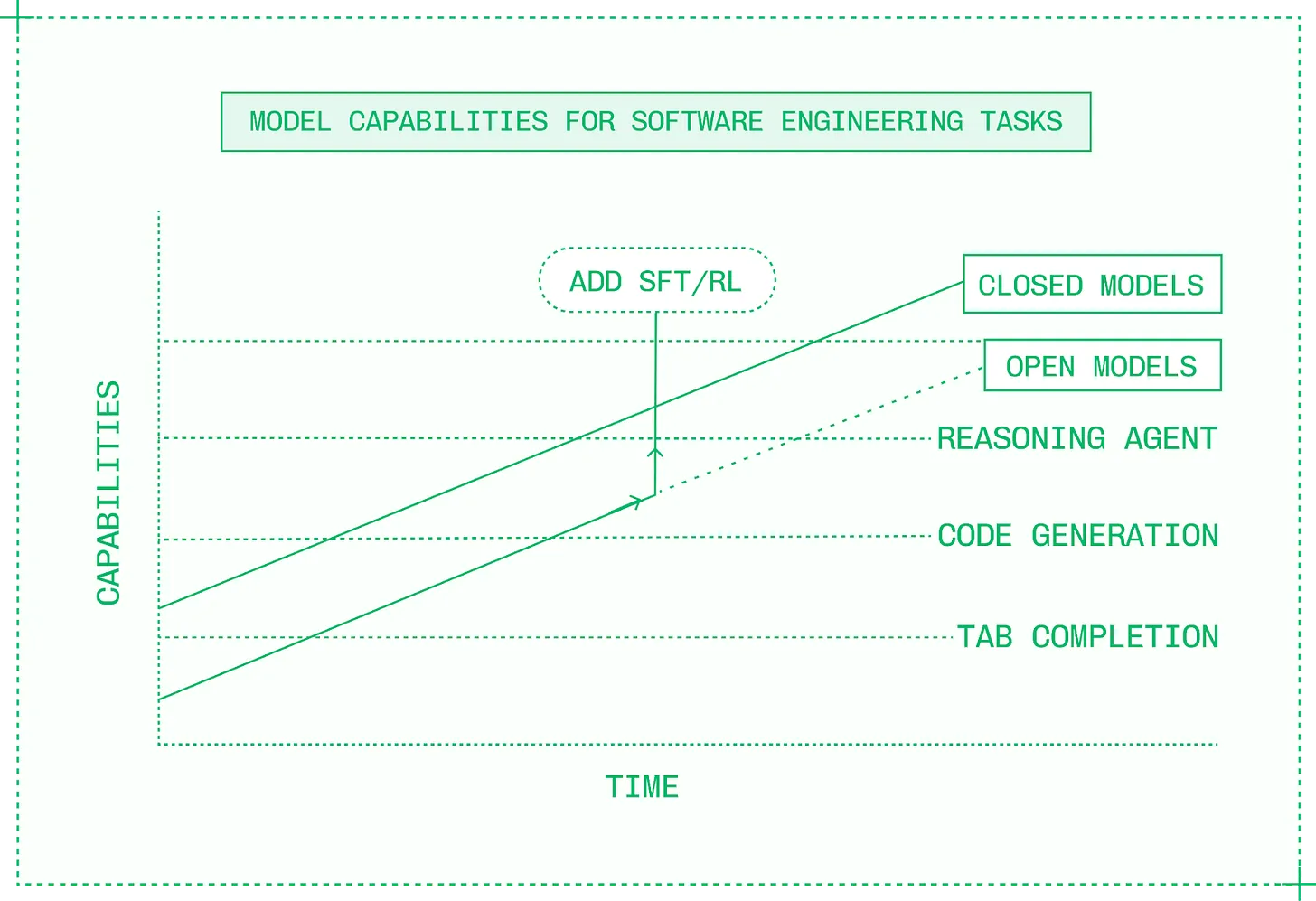 오픈 모델 커스터마이징을 통해 지연 시간, 신뢰성, 경제성에 대한 통제권 유지
오픈 모델 커스터마이징을 통해 지연 시간, 신뢰성, 경제성에 대한 통제권 유지
오픈 모델로 전환한다는 것은 추론 엔지니어링을 활용해 AI 제품을 구동하는 모델을 새로운 방식으로 개선할 기회가 생긴다는 뜻입니다.
- 지연 시간 (Latency): 폐쇄형 모델 API 는 처리량 (throughput) 을 위해 설계되었지만, 오픈 모델은 실시간 애플리케이션에 최적화할 수 있습니다.
- 가용성 (Availability): GPT 와 클로드 (Claude) API 가 99%(two nines) 의 가동 시간에 머무는 동안, 오픈 모델을 전용 배포하면 99.99%(four nines) 이상의 가동 시간을 달성할 수 있습니다.
- 비용 (Cost): 오픈 모델은 대규모 환경에서 대개 최소 80% 이상 저렴합니다.
따라서 3 년 전만 해도 추론 엔지니어링을 틈새 분야로 보았겠지만, 실제로는 진정으로 차별화되고 경쟁력 있는 AI 제품을 구축하려는 모든 기업에 추론 전략이 필요합니다. 커서 (Cursor), 클레이 (Clay), 감마 (Gamma), 머코어 (Mercor) 와 같은 AI 네이티브 스타트업들은 오픈 모델과 사내 모델을 기반으로 제품을 구축하며 초고속 성장의 정의를 다시 쓰고 있습니다. 노션 (Notion) 과 수휴먼 (Superhuman) 과 같은 선두 디지털 네이티브 기업들은 자사 제품을 카테고리 정의 제품으로 만드는 AI 기능을 심층 통합하여 성공을 거두었습니다. 그 밖에도 월드 랩스 (World Labs), 라이터 (Writer), 미라지 (Mirage) 등 수십 개의 새로운 세대 연구 및 엔지니어링 혼합 팀들이 자체 파운데이션 모델을 훈련하고 제품화하여 사업을 영위하고 있습니다.
전통적으로 새 기술 도입이 느렸던 기업 및 규제 산업에서도 도입세가 강합니다. 오픈이비던스 (OpenEvidence), 어브리지 (Abridge), 앰비언스 (Ambience) 와 같은 기업들은 의료 분야에서 생성형 AI 를 보편화하고 있으며, 세계 최대 기업들 사이에서도 AI 이니셔티브가 파일럿 단계를 넘어 대규모 사용자 채택 단계로 이동하고 있습니다.
추론에 대한 시장 전체의 수요는 개발자부터 임원에 이르기까지 모든 이에게 추론 엔지니어링을 배워 경력과 비즈니스를 발전시킬 기회를 제공합니다. 저는 지난 4 년간 베이스튼 (Baseten) 에서 역사상 가장 빠르게 변화하는 시장의 최전선에 앉아, 앞선 단락들에 언급된 모든 기업을 포함한 최고의 AI 제품들을 위해 미션 크리티컬한 추론을 지원하는 일을 해왔습니다.
희소식은 아직 초기 단계라는 점입니다. 여전히 추론 업무에 종사하는 전문가는 상대적으로 적고, 새로 진입하는 사람들도 빠르게 전문가가 될 수 있습니다. 또한 추론의 잠재력과 영향력은 갈수록 뚜렷해지고 있지만, 이 도메인은 여전히 초기 단계입니다. 이는 스택의 모든 수준에서 새롭고 흥미롭며 심층적인 기술적 문제들을 해결할 거대한 기회들이 있다는 뜻입니다.
2. 추론이란?
추론은 생성형 AI 모델 수명 주기의 두 번째 단계입니다.
- 훈련 (Training): 데이터로부터 모델 가중치를 학습하는 과정입니다.
- 추론 (Inference): 생성형 AI 모델을 프로덕션 환경에서 서빙하는 것입니다.
지난 10 년간의 머신러닝 (ML) 호황기에 수십만 명의 데이터 과학자와 ML 엔지니어가 ML 모델의 훈련과 추론이라는 전체 수명 주기에 익숙해졌습니다. 고전적인 ML 모델을 위한 추론은 비교적 간단합니다. 베이스튼 초기에는 XGBoost 와 같은 도구로 만들어진 모델을 가벼운 CPU 와 단순한 소프트웨어 스택으로 실했습니다.
반면, 생성형 AI 모델을 위한 추론은 복잡합니다. 모델 가중치를 가져와 GPU 몇 개를 준비한다고 해서 대규모 프로덕션 사용에 적합할 만큼 빠르고 안정적인 추론이 되지는 않습니다. 추론을 잘 수행하려면 세 가지 계층이 필요합니다.
- 런타임 (Runtime): 단일 GPU 지원 인스턴스에서 단일 모델의 성능을 최적화합니다.
- 인프라 (Infrastructure): 뛰어난 가동 시간을 유지하면서 실로 (silo) 를 만들지 않고 클러스터, 리전, 클라우드 전반에 걸쳐 확장합니다.
- 툴링 (Tooling): 추론을 담당하는 엔지니어들에게 통제력과 생산성의 균형을 맞출 수 있는 적절한 수준의 단순화를 제공합니다.
이 세 계층은 협력하여 대규모 미션 크리티컬 추론을 처리할 수 있는 시스템을 만들어야 합니다.
 완전한 추론 스택에는 런타임 및 인프라 최적화가 포함됨
완전한 추론 스택에는 런타임 및 인프라 최적화가 포함됨
런타임 계층은 GPU 하나 (또는 단일 인스턴스 내 여러 GPU) 에서 실행되는 개별 모델이 가능한 한 성능 좋고 효율적으로 작동하도록 보장합니다. 이 계층은 CUDA 부터 PyTorch, 그리고 vLLM, SGLang, TensorRT-LLM 과 같은 추론 엔진에 이르는 정교한 소프트웨어 스택에 의존합니다. FlashAttention 과 같은 커널이 상당한 성능 향상을 가져오므로 저수준 최적화가 중요합니다. 런타임 계층은 생성형 AI 모델의 추론 과제에 새로운 연구를 적용하는 여러 모델 성능 기법에 의존합니다.
- 배칭 (Batching): 들어오는 요청을 병렬로 실행하여 토큰 단위로 엮어 처리량을 높입니다.
- 캐싱 (Caching): 접두사를 공유하는 요청 간에 어텐션 알고리즘의 캐시된 결과인 KV 캐시를 재사용합니다.
- 양자화 (Quantization): 모델의 일부 부품의 정밀도를 낮추어 더 많은 연산 능력을 확보하고 메모리 부담을 줄입니다.
- 추론 (Speculation): 디코드 단계에서 순전파 (forward pass) 당 하나 이상의 토큰을 생성하기 위해 초안 토큰을 생성하고 검증합니다.
- 병렬화 (Parallelism): 새로운 병목 현상을 유발하지 않으면서 대형 모델을 가속화하기 위해 둘 이상의 GPU 를 효율적으로 활용합니다.
- 분리 (Disaggregation): LLM 추론의 두 단계인 사전 채움 (prefill) 과 디코드 (decode) 를 독립적으로 확장 가능한 워커로 분리합니다.
이러한 모델 성능 기법은 LLM 뿐만 아니라 비전 언어 모델, 임베딩 모델, 자동 음성 인식, 음성 합성, 이미지 생성, 비디오 생성 등 모든 양태 (modality) 에 사용되며, AI 시스템의 기능을 확장하고 각자 고유의 추론 최적화를 필요로 합니다.
하지만 이러한 런타임 최적화만으로는 부족합니다. 단일 모델 서버 인스턴스가 아무리 성능이 좋아도 결국 처리할 수 있는 것보다 많은 트래픽이 유입되기 때문입니다. 이는 CUDA 나 PyTorch 의 문제가 아니라 인프라 계층에서 해결해야 할 시스템 문제입니다.
인프라 문제는 규모 수준에 따라 그 성질이 달라집니다. 초기에는 자동 확장 (autoscaling) 에 대한 문제가 발생합니다. 언제 복제본 (replica) 을 추가하고 제거해야 하는지, 그리고 이를 얼마나 신속하게 수행할지 파악하는 것입니다. 특정 규모 (대개 GPU 수백 개) 를 넘어서면 인프라 문제는 용량 (capacity) 에 의해 정의됩니다. 충분한 GPU 에 접근하기 위해 추론 엔지니어들은 워크로드를 여러 리전과 클라우드 제공업체에 분산하기 시작합니다. 이는 곧바로 사일로 (silo) 현상을 초래합니다. 한 클러스터의 모델은 리소스 부족에 허덕이는 동안 다른 클러스터에는 미사용 용량이 남게 됩니다. 인프라 확장의 마지막 단계는 사용 가능한 모든 리소스를 단일 통합 연산 풀 (unified pool of compute) 로 취급하는 글로벌 시스템입니다. 사려 깊은 멀티 클라우드 인프라는 개별 리전이나 클라우드 제공업체의 다운타임으로부터 보호하여 신뢰성을 향상시킵니다. 또한 글로벌 애플리케이션의 경우 최종 사용자와 가까운 곳에서 추론을 실행하면 종단 간 지연 시간을 개선할 수 있습니다.
이러한 런타임 및 인프라 기능이 구축되면, 이를 적절한 수준의 단순화 (abstraction) 로 제공해야 합니다. 베이스튼과 같은 추론 제공업체나 사내 추론 팀은 완전한 추론 플랫폼의 세 번째 핵심 계층인 어떤 툴링와 개발자 경험을 제공할지 고려해야 합니다.
물론 개발자 경험은 주관적입니다. 추론에 있어 한 극단은 블랙박스입니다. 플랫폼에 모델 가중치를 건네면 API 가 반환되는 방식입니다. 또 다른 극단은 연산, 네트워크, 디스크 등에 대한 기본 구성 요소만 제공하는 것입니다. 올바른 개발자 경험은 그 중간 어딘가에 있습니다. 추론 엔지니어가 미션 크리티컬한 추론을 자신 있게 실행할 만큼의 통제력을 가지면서도, 생산적으로 작업할 수 있을 만큼의 단순화를 갖춘 상태입니다.
추론 엔지니어링 (Inference Engineering) 발췌본인 이 아티클은 런타임, 인프라, 툴링이라는 세 계층 전반에 걸쳐 추론을 구동하는 기술과 기법의 개요를 제시합니다.
3. 언제 추론 엔지니어링이 필요한가?
추론 엔지니어링은 생성형 모델의 프로덕션 서빙을 최적화하여 AI 제품에 속도와 확장성을 더합니다. 최적화란 다양한 옵션 중 최선의 해결책을 찾는 것을 의미합니다. 모델 성능을 최적화하고 견고한 인프라를 구축하기 전에, 귀사의 제품에 있어 '최선'가 무엇을 의미하는지 알아야 합니다. 성능 개선의 상당 부분은 지연 시간, 처리량, 품질 간의 절충 (tradeoff) 을 통해 이루어지기 때문입니다.
실제로 최적화는 단일 요소를 극대화하는 것이 아니라 올바른 균형을 찾는 경우가 많습니다. 예를 들어 NFL 선수들은 덩치가 크고 빠르며 강합니다. 하지만 스모 선수만큼 크거나, 올림픽 육상 선수만큼 빠르거나, 역도 챔피언만큼 강하지는 않습니다. 그들의 몸과 기술은 전체 시즌 동안 포지션의 특정 요구사항을 충족하도록 최적화되어 있습니다.
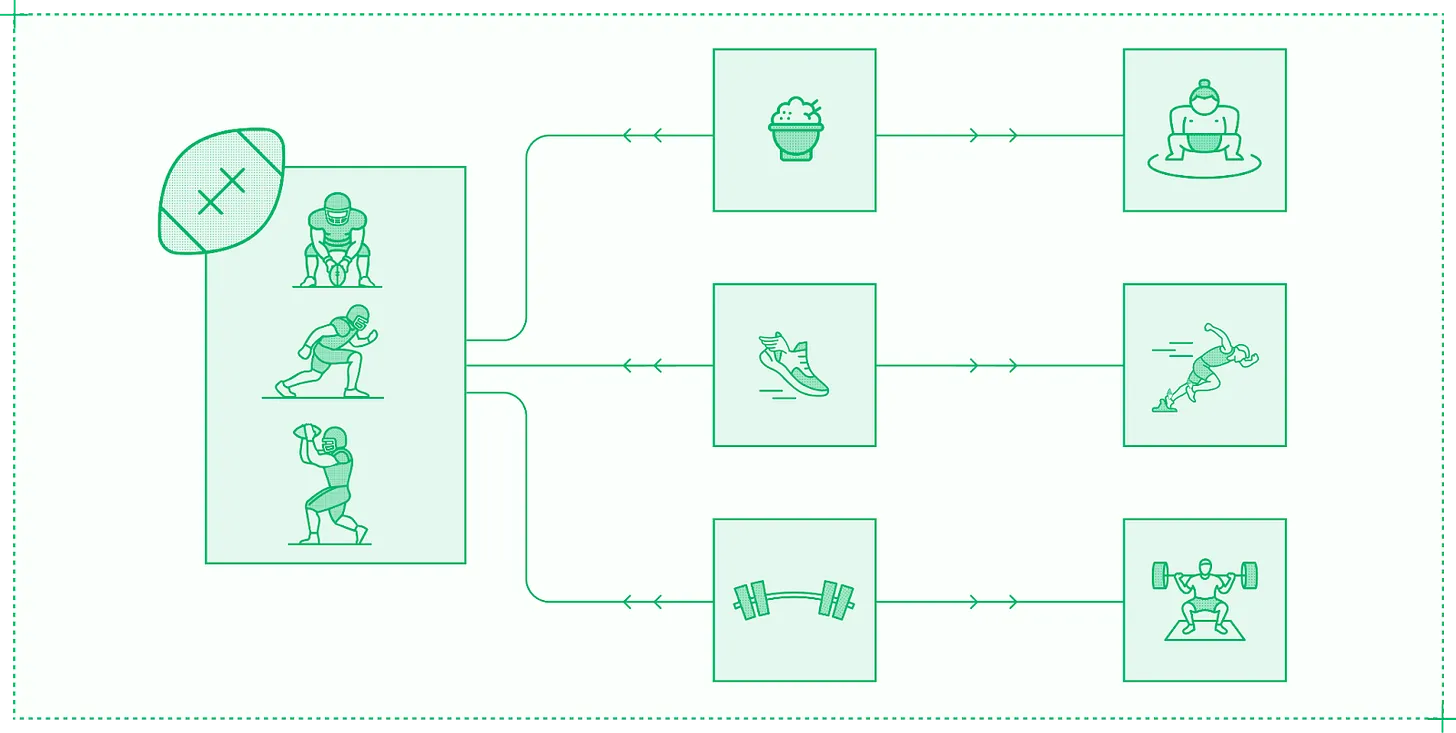 엘리트 운동선수처럼 추론 서비스도 워크로드의 요구사항에 맞춰 특화되어야 함
엘리트 운동선수처럼 추론 서비스도 워크로드의 요구사항에 맞춰 특화되어야 함
마찬가지로 귀사의 추론 시스템도 모델, 제품, 트래픽의 특정 요구사항을 충족하도록 최적화되어야 합니다. 제약 조건을 더 많이 도입할수록 더 나은 결과를 달성할 수 있습니다. 다음 사항을 알아야 합니다.
- 모델 요구사항: 추론을 실행해야 할 모델은 무엇입니까?
- 애플리케이션 인터페이스: 입력는 어떻게 모델에 전달되며, 출력는 어떻게 포맷되어야 합니까?
- 지연 시간 예산: 제품이 사용자 작업에 종단 간 (end-to-end) 으로 얼마나 빠르게 응답해야 합니까?
- 단위 경제성 (Unit economics): 요청당, 사용자당 또는 월 단위로 비용을 지출하는 것이 얼마나 타당합니까?
- 사용 패턴: 동시 사용자는 몇 명이며, 사용 패턴 (예: 업무 시간 중 활동 증가) 이 있습니까?
AI 제품 구축 초기에는 이러한 질문에 대한 답이 명확하지 않을 수 있습니다. 이 시점에는 전용 추론에 투자하기보다 가능한 한 기성 API 를 사용하는 것이 낫습니다. 하지만 제품이 확장되면 요구사항이 명확해지고, 추론 엔지니어링은 가치 있는 과제가 됩니다.
4. 추론에는 어떤 하드웨어가 사용되는가?
추론 엔지니어링은 가속기 (accelerator) 에 의존합니다. 이는 수 테라바이트의 데이터를 적재하고 초당 수조 회 연산을 수행하도록 설계된 강력한 하드웨어입니다. 추론에 가장 일반적으로 사용되는 가속기는 GPU 이며, 추론용 GPU 시장 선두 주자는 NVIDIA 입니다. 제 책은 데이터센터 내 NVIDIA GPU 를 위한 추론 엔지니어링에 초점을 맞추며, 기타 데이터센터 가속기 공급업체와 로컬 추론도 다룹니다.
공급업체를 막론하고 시장에는 세 가지 유형의 GPU 가 있습니다.
- 데이터센터용 GPU: 상호 연결된 고성능 GPU 가 탑재된 랙형 서버입니다. 예: NVIDIA B200.
- 워크스테이션용 GPU: 전문 워크플로우를 위한 개별 데스크탑 GPU 입니다. 예: NVIDIA RTX Pro 6000.
- 개인용 컴퓨팅 GPU: 일상적인 사용을 위한 개별 데스크탑 GPU 입니다. 예: NVIDIA GeForce RTX 5090.
대규모 추론은 랙에 장착된 데이터센터용 GPU 를 사용합니다. 이는 표준화된 전원, 네트워킹, 냉각 장치를 갖춘 냉장고 크기의 섀시입니다. NVIDIA B200 과 같은 데이터센터용 GPU 는 개별 성능이 가장 높을 뿐만 아니라, 고대역폭 GPU 간 상호 연결을 포함하며, 매우 표준화된 구성으로 설치되고 전 세계 데이터센터에서 수백만 개 단위로 이용 가능합니다.
여러분 책상 밑에서 B200 GPU 가 돌아간다면 제게 사진을 보내주시길 바랍니다! (그런 일은 없겠지만요.) 대신 데이터센터용 GPU 에 의한 추론은 다음 세 가지 모드 중 하나로 실행됩니다.
- 클라우드: AWS 나 GCP 같은 하이퍼스케일러나, 코위브 (CoreWeave), 네비우스 (Nebius) 같은 네오 클라우드 (neocloud) 와 같이 타인의 데이터센터에서 GPU 를 임대합니다.
- 온프레미스 (On-premises): 직접 관리하는 데이터센터에 GPU 를 구매하여 설치합니다.
- 공기 차단 (Air-gapped): 온프레미스에 설치되어 추론을 실행하기 위해 물리적으로 GPU 에 접근해야 합니다.
대부분의 추론 엔지니어는 클라우드 GPU 를 사용합니다. 대기업과 정부는 온프레미스 및 공기 차단 배포를 실행하지만, 클라우드 기반 GPU 는 급성장하는 AI 제품에 필요한 확장성을 위한 유연성과 접근성을 제공합니다.
제약 조건이 있더라도 하드웨어 환경을 탐색하는 것은 복잡합니다. 클라우드 제공업체 간의 차이부터 NVIDIA 의 독특한 네이밍 규칙에 이르기까지 올바른 가속기를 선택하는 데는 많은 미묘한 차이가 있습니다.
5. 추론에는 어떤 소프트웨어가 사용되는가?
추론 공간에서 NVIDIA 의 시장 지배력은 하드웨어를 중심으로 한 견고하고 성숙한 소프트웨어 생태계에 힘바가 큽니다. 하드웨어 반복 주기는 느립니다. 애플이나 NVIDIA 와 같은 최고 수준의 하드웨어 기업들은 기껏해야 연 1 회, 보통은 2 년 주기로 새로운 아키텍처와 세대를 출시합니다. 하지만 소프트웨어 반복은 빠릅니다. 종종 새로 출시된 오픈 모델을 첫날부터 실행하려면, 새 모델을 지원받기 위해 각 소프트웨어 종속성의 야간 빌드 (nightly build) 나 기타 사전 릴리스 버전을 설치해야 합니다.
소프트웨어의 빠른 반복 주기와 낮은 진입 장벽은 추론 엔지니어링의 지형을 극적으로 확장합니다. 소수의 경쟁사를 중심으로 한 하드웨어와 대조적으로, 추론 스택의 다양한 수준에서 소프트웨어를 구축하는 무수한 기업들이 있습니다.
추론 엔지니어들에게 주요 소프트웨어 플레이어는 다음과 같습니다.
- NVIDIA: CUDA 부터 다이나모 (Dynamo) 에 이르기까지 때로는 독점적인 자사 소프트웨어 생태계에 막대하게 투자합니다.
- 허깅페이스 (Hugging Face): 모든 오픈 모델에 대한 모델 레지스트리와 트랜스포머 (transformers)(트랜스포머 아키텍처 기반 모델), 디퓨저 (diffusers)(디퓨전 기반 (diffusion-based) 생성 모델) 를 유지 관리합니다.
- 리눅스 재단 (The Linux Foundation): PyTorch 나 vLLM 과 같은 하드웨어 중립적 프로젝트를 유지 관리합니다.
- LMSYS Org: 추론과 평가에 필수적인 도구, 특히 SGLang 을 개발합니다.
수천 개 이상의 기업, 대학, 연구 기관들이 추론에 필수적인 오픈소스 기여를 하고 있습니다. 시간이 지남에 따라 기술들은 점점 더 높은 수준의 단순화 (abstraction) 로 구축되었습니다.
- CUDA: 연산과 메모리에 대한 명시적 제어를 위해 GPU 와 직접 통신합니다.
- 딥러닝 프레임워크: Python 에서 신경망을 훈련, 내보내기, 실행하기 위한 CUDA 위의 단순화 계층입니다.
- 추론 엔진: 일반적인 아키텍처를 위해 고도로 구성 가능한 PyTorch 기반 추론을 제공합니다.
- NVIDIA Dynamo: 대규모 배포를 지원하기 위해 추론 엔진 위에 위치합니다.
현재의 추론 엔지니어링 대부분은 추론 엔진을 구성하고 배포하며, 여러 GPU 에 걸쳐 추론을 오케스트레이션하는 더 높은 수준의 단순화 계층에서 이루어집니다. 스택의 어느 수준에서 작업하든, 인접한 단순화 수준에 대한 강력한 멘탈 모델을 갖추는 것이 업무를 이끄는 데 필수적입니다.
6. 추론에는 어떤 인프라가 필요한가?
프로덕션 트래픽을 확장하면 가정들이 철저히 검증받습니다. 입력 및 출력 시퀀스 길이부터 트래픽 패턴, 사용자가 채팅하려는 주제에 이르기까지 모든 것이 프로덕션에서 관찰되는 성능에 영향을 미칩니다. 그리고 안전하고 견고한 인프라를 유지하는 것은 GPU 에서 모델 추론을 최적화하는 것과는 완전히 다른 기술 세트 (skillset) 입니다.
단일 인스턴스가 아무리 빠르고 효율적으로 모델을 서빙하더라도, 트래픽이 충분히 높아지면 서비스는 압도당합니다. 이는 PyTorch 나 CUDA 의 문제가 아니라 인프라 문제이며, 다른 마인드셋과 기술이 필요합니다.
프로덕션 확장은 GPU 를 어디서 어떻게 확보하고, 트래픽을 어떻게 분산하며, 다운타임을 어떻게 방지할지에 대한 새로운 복잡성을 가져옵니다. 자동 확장의 목표는 유휴 GPU 에 돈을 낭비하지 않으면서 지연 시간 SLA 를 유지하고 모든 들어오는 요청을 서빙할 수 있는 리소스를 항상 보유하도록 하는 것입니다.
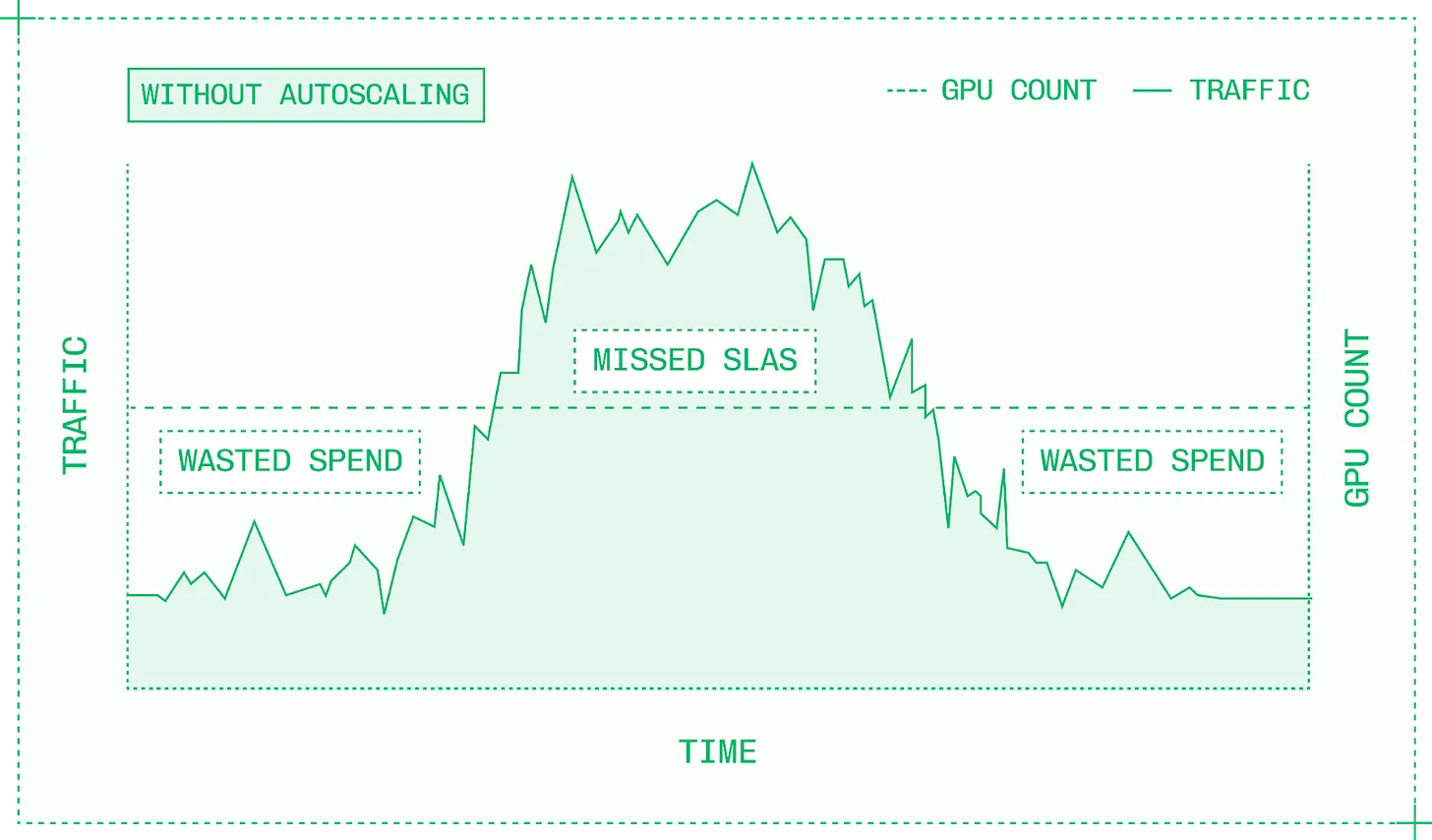 자동 확장이 없으면 트래픽이 뜸할 때는 리소스를 낭비하고, 트래픽 급증 시에는 SLA 를 놓치게 됨
자동 확장이 없으면 트래픽이 뜸할 때는 리소스를 낭비하고, 트래픽 급증 시에는 SLA 를 놓치게 됨
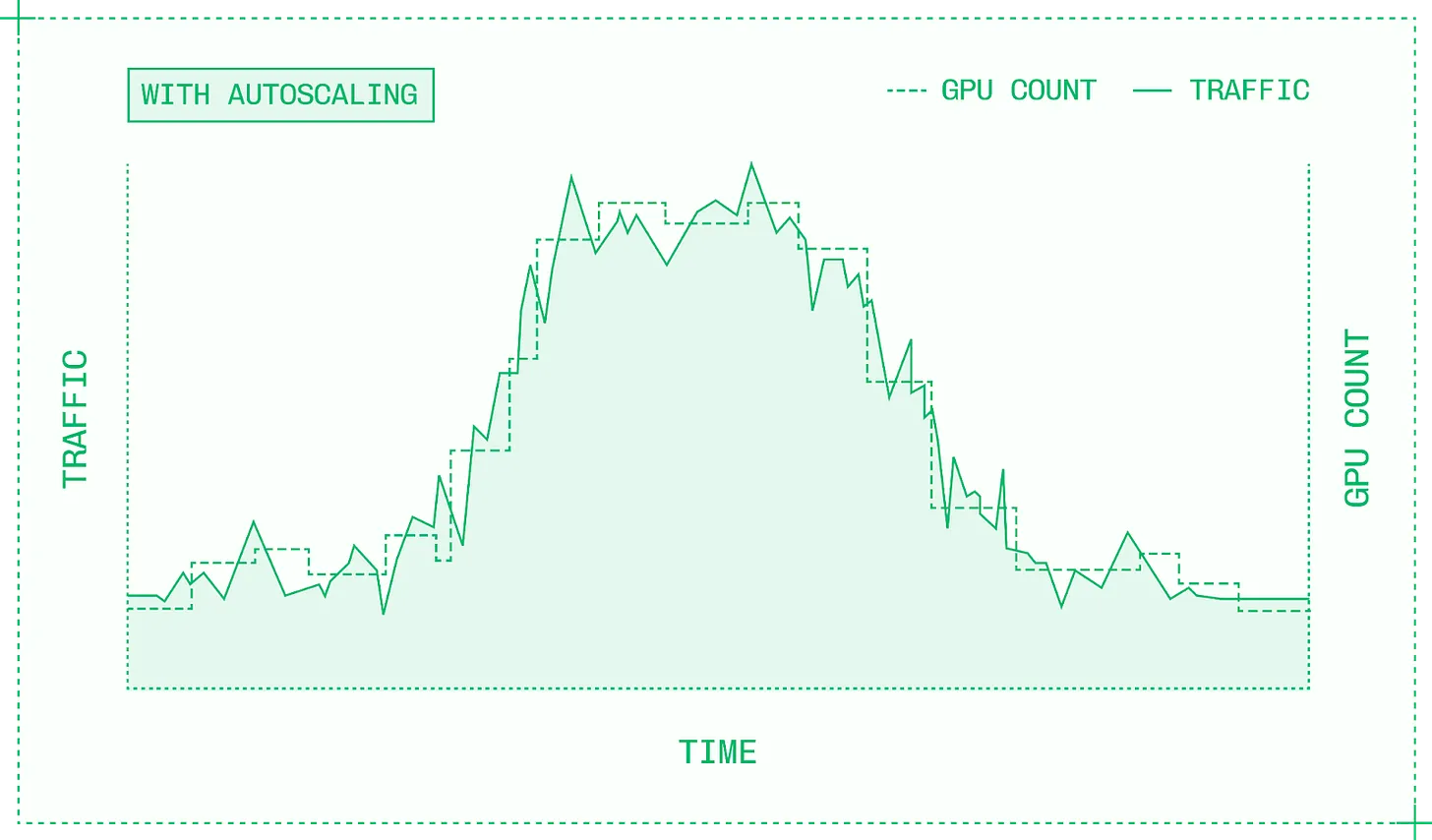 추론을 위한 강력한 자동 확장 시스템은 리소스를 수요에 맞춥니다
추론을 위한 강력한 자동 확장 시스템은 리소스를 수요에 맞춥니다
자동 확장 시스템은 오픈소스 컨테이너 오케스트레이션 시스템인 쿠버네티스 (Kubernetes) 와 컴퓨팅 프로비저닝 및 할당 해제를 위한 클러스터 수준 시스템을 함께 사용합니다. 쿠버네티스는 각기 자체 인스턴스에서 실행되는 모델 컨테이너의 복제본을 하나 이상 실행할 수 있습니다. 인스턴스에는 컨테이너에 필요한 GPU 및 기타 하드웨어 리소스가 포함됩니다.
트래픽이 비정상적으로 일정하지 않는 한, 필요에 완벽하게 부합하는 특정한 수의 복제본은 존재하지 않을 것입니다. 자동 확장이란 클러스터 내 주어진 모델에 할당된 복제본 수를 동적으로 조정하는 관행입니다.
자동 확장 결정을 내리는 두 가지 방법이 있습니다.
- 사용량 (Utilization): 메모리 사용량이나 연산 사용량 같은 GPU 사용량 신호를 기반으로 확장 또는 축소합니다.
- 트래픽 (Traffic): 시스템에서 처리 중인 요청 수를 기반으로 확장 또는 축소합니다.
사용량과 트래픽은 항상 일치하지는 않습니다. 예를 들어 LLM 사전 채움 (prefill) 단계에서는 캐시되지 않은 입력 토큰이 수십만 개인 몇 안 되는 요청이, 캐시 적중률이 높은 많은 수의 작은 요청보다 훨씬 높은 사용량을 유발할 수 있습니다. 트래픽 기반 확장 결정은 선제적으로 이루어질 수 있지만, 사용량은 후행 지표 (lagging indicator) 입니다. 시스템 리소스를 수요와 일치시키려면 두 가지를 조합해 사용해야 합니다.
트래픽 기반 자동 확장 시스템을 설계할 때는 다음 다섯 가지 요소를 구성해야 합니다.
- 최소 복제본 (Min replicas): 트래픽과 무관하게 항상 실행되는 최소 복제본 수는 얼마입니까?
- 최대 복제본 (Max replicas): 트래픽이 많을 때 할당할 수 있는 최대 복제본 수는 얼마입니까?
- 자동 확장 창 (Autoscaling window): 트래픽을 측정하고 자동 확장 결정을 내리는 데 사용되는 슬라이딩 시간 범위는 얼마나 됩니까?
- 축소 지연 시간 (Scale down delay): 축소 제안 후 또 다른 트래픽 급증을 대비해 얼마나 대기합니까?
- 동시성 목표 (Concurrency target): 각 복제본이 한 번에 몇 개의 요청을 처리할 수 있습니까?
정확한 구성은 자동 확장 시스템이 리소스 낭비 없이 지연 시간 SLA 를 유지한다는 목표를 얼마나 잘 달성하는지 결정합니다. 예를 들어, 축소 지연 시간을 늘리면 들쑥날쑥한 트래픽에 대한 성급한 축소를 방지할 수 있지만, 트래픽이 진정된 후에도 불필요한 비용이 발생할 수 있습니다.
단일 클러스터 내 자동 확장은 특정 시점까지는 효과가 있지만, 전 세계 사용자를 대상으로 하는 대용량 배포은 전 세계에 분산된 수천 개의 GPU 가 필요합니다. 서로 다른 클라우드 제공업체 간에 고립된 연산의 집합으로 멀티 클라우드 추론을 구축하는 것은 간단합니다. 그러나 이러한 설정에서는 클라우드 간 연산을 유연하게 사용할 방법이 없으며, 워크로드를 클라우드 간에 이동하는 것은 지루하고 오류가 발생하기 쉬운 과정입니다.
진정한 멀티 클라우드 추론은 별도의 연산 풀들을 호환 가능한 (fungible) 것으로 취급하는 다품종 소량 (multi-region), 다품종 (multi-provider) 빈 채우기 (bin packing) 도구를 구축해야 합니다. 단일 클러스터 내의 쿠버네티스와 마찬가지로 멀티 클라우드 용량 관리는 글로벌 스케줄링을 가능하게 하는 글로벌 관점을 취해야 합니다.
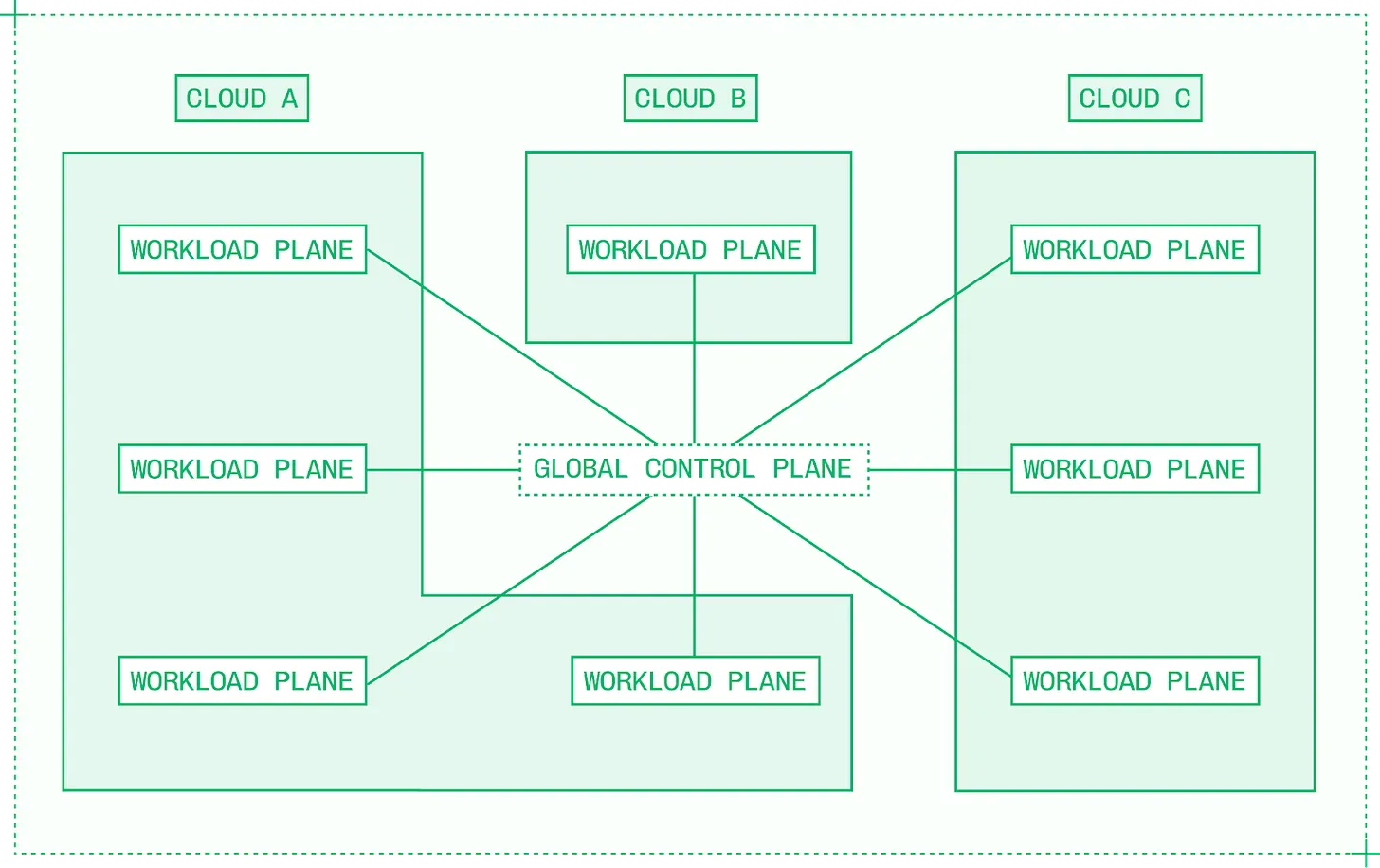 멀티 클라우드 접근 방식은 제어 및 워크로드 플레인 개념을 멀티 클러스터, 멀티 리전 시스템으로 확장
멀티 클라우드 접근 방식은 제어 및 워크로드 플레인 개념을 멀티 클러스터, 멀티 리전 시스템으로 확장
진정한 멀티 클라우드 추론을 실행하면 다음과 같은 이점을 얻을 수 있습니다.
- 용량 (Capacity): 보다 크고 유연한 GPU 접근을 위해 여러 제공업체의 용량을 풀링합니다.
- 중복성 (Redundancy): 중단에 대한 복원력을 위해 추론을 제공업체 간에 분산시킵니다.
- 지연 시간 (Latency): 네트워크 지연 오버헤드를 줄이기 위해 최종 사용자와 가까운 곳에서 추론을 실행합니다.
- 규정 준수 (Compliance): 데이터 주권 및 기타 규제 요구사항을 준수하며 추론을 실행합니다.
한 클라우드의 단일 클러스터에서 여러 클라우드의 여러 클러스터로 확장하려면 새로운 조정 계층이 필요합니다. 멀티 클라우드 아키텍처에는 다음이 포함됩니다.
- 제어 플레인 (Control plane): 모델 배포와 글로벌 확장 결정을 처리하고 실시간 이벤트 스트림을 수신합니다.
- 워크로드 플레인 (Workload planes): 직접적인 추론 트래픽과 클러스터 내 확장 결정을 처리하며, 사용량과 수요를 보고합니다.
이러한 책임의 분리는 개별 워크로드 플레인이 독립적으로 트래픽을 서빙할 수 있도록 보장합니다. 제어 플레인이나 특정 워크로드 플레인에 문제가 발생하더라도 다른 워크로드는 영향을 받지 않아야 합니다.
7. 추론을 빠르게 하는 5 가지 접근법
추론 엔지니어링 분야에서 일할 때 가장 멋진 점 중 하나는, 새로운 학술 연구가 채택되는 데 수년에서 수십 년이 걸리는 다른 많은 산업과 달리, 새 논문들의 기법이 수개월 아니 며칠 만에 프로덕션에 적용된다는 점입니다. 하지만 연구와 프로덕션 사이에는 간극이 존재하며, 가장 가시적인 추론 엔지니어링 작업 중 일부는 바로 그 간극을 메우는 데서 나옵니다.
현실 세계의 트래픽은 제약 조건을 따르지 않습니다. 하지만 볼륨이 생기면 시간이 지남에 따라 시스템을 적응시켜 변화하는 사용 양상에 맞출 수 있습니다. 추론 엔진, 추론 (speculation) 알고리즘, 모델 서버의 매개변수를 튜닝하는 일은 일회성 작업이 아닙니다. 대신 반복적인 배포나 동적 런타임 조정을 통해 추론 시스템의 성능을 지속적으로 개선할 수 있습니다. 올바른 기법과 구성의 조합을 찾는 것은 인내심 있는 실험을 필요로 합니다.
베이스튼의 한 추론 엔지니어가 코드 자동완성 모델을 작업하던 사내 해커톤이 기억납니다. 그 엔지니어는 손으로 쓴 스크립트로 무려 77 가지 서로 다른 구성을 시도한 끝에, 상식적이지 않은 해결책을 찾아내어 고객 모델의 TPS(초당 토큰 수) 를 두 배로 높였습니다.
때로는 기법들이 공생 관계를 이루기도 하고 상충되기도 하여, 추론 최적화는 더욱 복잡해집니다. 예를 들어, KV 캐시를 양자화하면 분리 (disaggregation) 의 병목 현상을 완화하지만, 배치 크기를 늘리면 추론 (speculation) 에 사용 가능한 연산 능력이 줄어듭니다. 추론 엔지니어의 과제는 항상 부분의 합보다 큰 효과를 내는 균형 잡힌 최적화 세트를 만드는 것입니다.
추론 가속화를 위한 응용 연구의 주요 범주인 양자화, 추론 (speculation), 캐싱, 병렬화, 분리에 대해 살펴보겠습니다.
접근법 #1: 양자화 (Quantization)
양자화는 모델 가중치의 수치 정밀도를 낮추는 것을 의미합니다. 이는 지연 시간 (TTFT [첫 번째 토큰까지의 시간] 및 TPS 모두) 을 개선하고 시스템 처리량을 높이며, 분리, 추론, 접두사 캐싱과 같은 다른 최적화 기법들이 더욱 효과적일 수 있는 여력을 만들어 줍니다. 하지만 잘못될 경우 양자화는 모델의 출력 품질을 현저하게 저하시킬 수 있습니다.
모델은 가중치, 활성화 (activation) 및 기타 구성 요소가 특정한 기본 숫자 형식으로 표현된 상태로 훈련됩니다. 대개 BF16 이나 FP16 이지만, 훈련에는 8 비트 및 4 비트 기본 정밀도도 점점 더 널리 쓰이고 있습니다. 훈련 후 양자화 (Post-training quantization) 는 이러한 모델 가중치와 기타 값들을 기본 숫자 형식에서 더 낮은 정밀도의 형식으로 변경하여 작동합니다. 정밀도를 절반으로 줄이면 추론의 두 단계 모두에서 성능이 향상됩니다.
- Prefill(사전 채움): 연산 집약적인 (compute-bound) 사전 채움이 이제 2 배의 FLOPS 를 가진 저정밀도 텐서 코어에서 실행됩니다.
- Decode(디코드): 메모리 집약적인 (memory-bound) 디코드는 이제 값당 절반의 데이터만 로드하므로 실효 메모리 대역폭이 두 배가 됩니다.
양자화된 데이터로 작업하면 오버헤드가 발생하므로, 16 비트에서 8 비트로 가더라도 선형적으로 2 배 빨라지는 것은 아닙니다. 실제로 정밀도를 한 단계 낮추는 양자화는 대개 LLM 의 성능을 30~50% 향상시킵니다.
양자화의 걸림돌은 모델의 출력 품질을 저하시킬 위험이 있으며, 추론을 지탱하는 계산 전반에 정밀도 오류를 발생시킬 가능성이 있다는 점입니다. 정밀도 오류는 시간이 지남에 따라 누적됩니다. 파이 (Pi) 값을 서로 다른 정밀도로 제곱하고 세제곱했을 때 어떤 일이 일어나는지 보십시오.
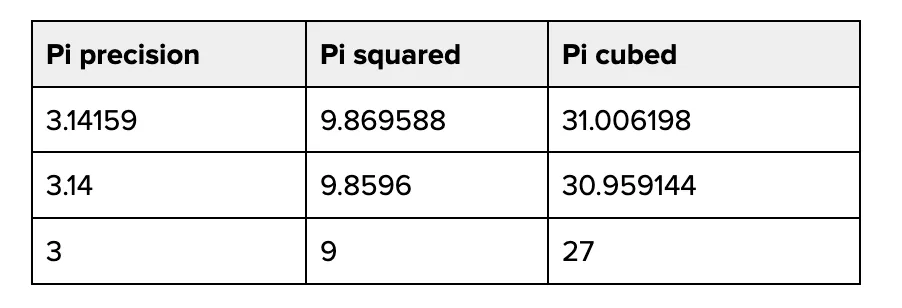 양자화 작업의 대부분은 정밀도 오류를 방지하고 최종 모델 출력에 미치는 영향을 최소화하는 데 집중됩니다.
양자화 작업의 대부분은 정밀도 오류를 방지하고 최종 모델 출력에 미치는 영향을 최소화하는 데 집중됩니다.
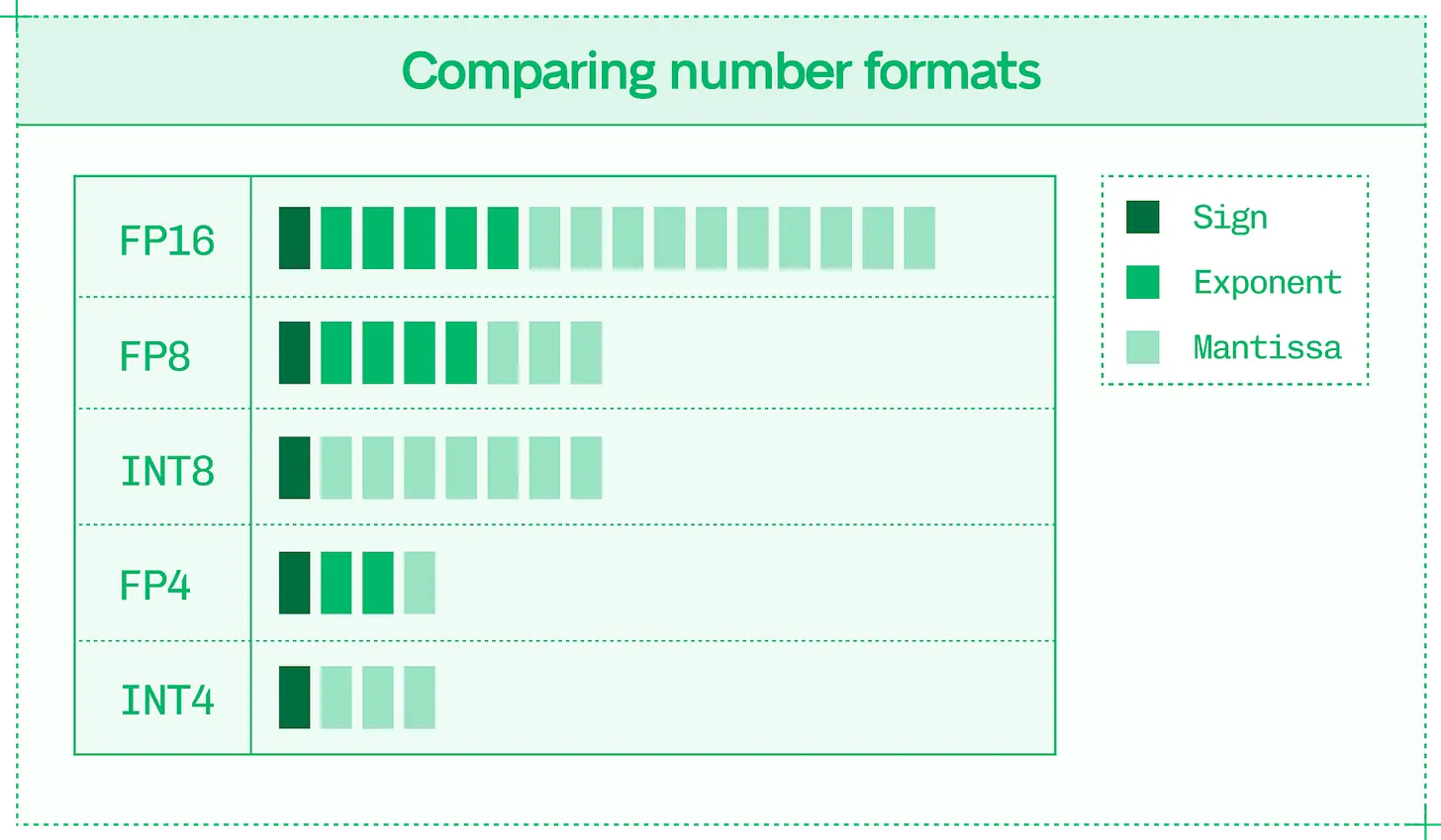
16 비트, 8 비트, 4 비트 정밀도가 추론의 주요 형식입니다. 숫자 형식은 다음을 포함합니다.
- 정밀도 (Precision): 형식에서 단일 값을 표현하는 데 사용되는 비트 수입니다. 예: FP16 은 16 비트를 사용합니다.
- 유형 (Type): 이러한 비트가 정수 (소수점 없음) 를 나타내는지 부동 소수점 (소수점 있음) 을 나타내는지 여부입니다.
- 축척 인자 (Scale factor): 저정밀도 형식의 값을 고정밀도 형식으로 다시 매핑하는 데 사용되는 승수입니다.
이러한 속성들이 결합되어 숫자 형식이 추론에 사용되는 값을 얼마나 잘 표현하는지를 결정하는 두 가지 요소를 결정합니다.
- 다이나믹 레인지 (Dynamic range): 형식으로 표현할 수 있는 최솟값과 최댓값의 차이입니다.
- 세분화 (Granularity): 단일 축척 인자를 따라 양자화되는 파라미터 또는 기타 값의 수입니다.
다이나믹 레인지는 품질 손실 없는 저정밀도 추론에 필수적입니다. 16 비트는 65,536 개의 서로 다른 값을 표현할 수 있지만, 8 비트는 256 개만 표현할 수 있습니다. 다이나믹 레인지는 이러한 값들의 분포, 즉 사용 가능한 최솟값과 최댓값의 차이를 의미합니다. 이는 부동 소수점 형식이 정수 형식보다 추론에 더 우수한 이유를 설명합니다. 부동 소수점 형식에는 세 가지 속성이 있습니다.
- 부호 (Sign): 숫자의 양수를 나타내는 단일 비트입니다.
- 지수 (Exponent): 함께 지수 인자를 나타내는 비트 세트입니다.
- 가수 (Mantissa): 2 의 지수승을 곱한 기저 값을 함께 나타내는 비트 세트입니다.
E4M3 데이터 형식의 FP8 숫자는 4 비트 지수와 3 비트 가수, 나머지 1 비트는 부호를 위해 사용됩니다. 정수 형식에는 부호와 값 비트만 있습니다.
 부동 소수점 숫자 형식은 부호 비트와 함께 지수 및 가수 비트를 가짐
부동 소수점 숫자 형식은 부호 비트와 함께 지수 및 가수 비트를 가짐
부동 소수점 숫자의 지수는 더 높은 다이나믹 레인지를 제공하므로 매우 크거나 매우 작은 숫자를 더 잘 표현할 수 있습니다. 이는 이상치 (outlier) 값이 추론에서 중요하며, 부동 소수점 숫자 형식이 양자화 후에도 이상치를 더 잘 표현하기 때문에 중요합니다.
부동 소수점 형식 내에서도 FP4, MXFP4, NVFP4 와 같이 각 정밀도마다 여러 옵션이 있습니다. 이러한 형식들은 세분화, 즉 단일 축척 인자로 양자화되는 값의 수에서 차이가 납니다.
양자화는 세 수준에서 적용될 수 있습니다.
- 텐서 수준 (Tensor level): 전체 QKV 텐서에 대해 단일 축척 인자를 계산합니다.
- 채널 수준 (Channel level): 텐서 내의 각 특성 벡터 (feature vector) 에 대해 서로 다른 축척 인자를 계산합니다.
- 블록 수준 (Block level): 각 특성 벡터 내에서 N 개 값의 블록으로 나누고 각 블록에 대한 축척 인자를 계산합니다.
더 세분화된 양자화는 이상치를 매끄럽 만들어버릴 가능성을 낮춰 품질을 보존합니다. 하지만 더 많은 세분화는 축척 인자를 저장하고 적용하기 위한 추가 오버헤드를 초래합니다.
모델의 구성 요소들은 양자화에 대해 각기 다른 민감도를 가집니다. 더 민감한 구성 요소의 정밀도를 낮추면 품질 저하 위험이 더 높습니다. 덜 민감한 순서에서 더 민감한 순서로는 다음과 같습니다.
- 가중치 (Weights): 선형 레이어는 양자화에 가장 덜 민감합니다.
- 활성화 (Activations): 활성화 함수의 중간 출력은 양자화에 어느 정도 민감합니다. 모델 가중치에 비해 극히 일부이므로 드물게 양자화됩니다.
- KV 캐시: 어텐션 계산에서 캐시된 값은 양자화에 중간 정도 민감합니다.
- 어텐션 (Attention): 모델의 어텐션 레이어는 양자화에 매우 민감하며, 특히 소프트맥스 (softmax) 와 같은 수식이 그렇습니다.
각 구성 요소 내에서도 양자화를 더 선별적으로 적용할 수 있습니다. 선형 레이어와 활성화는 크기가 크기 때문에 대체로 양자화에 덜 민감하지만, 신경망의 입력 및 출력 레이어와 같은 초기 및 후기 레이어는 더 민감하므로 원래 정밀도로 유지될 수 있습니다.
가중치와 활성화의 양자화가 성능 향상에 도움이 되지만, KV 캐시 양자화는 접두사 캐싱 및 분리와 같은 기법에 추가 부스트를 제공합니다. KV 캐시는 귀중한 리소스이며, 이를 양자화하면 추론 엔진이 이를 메모리에 더 많이 저장하고 더 빠르게 읽을 수 있습니다. 하지만 각 토큰의 KV 캐시는 후속 토큰마다 사용됩니다. 이는 양자화로 인한 정밀도 오류가 토큰에서 토큰으로 누적될 수 있음을 의미합니다.
이러한 누적 오류가 바로 어텐션 레이어가 양자화에 가장 위험한 이유입니다. 어텐션은 다이나믹 레인지에 매우 민감할 뿐만 아니라, 각 어텐션 계산이 이전 어텐션 계산의 결과에 의존하기 때문입니다. 따라서 수천 개의 토큰 시퀀스 전체에 걸쳐 오류가 급속히 누적됩니다. 가장 공격적인 양자화 방식을 제외한 모든 방식은 소프트맥스와 같은 함수를 원래 정밀도로 실행합니다.
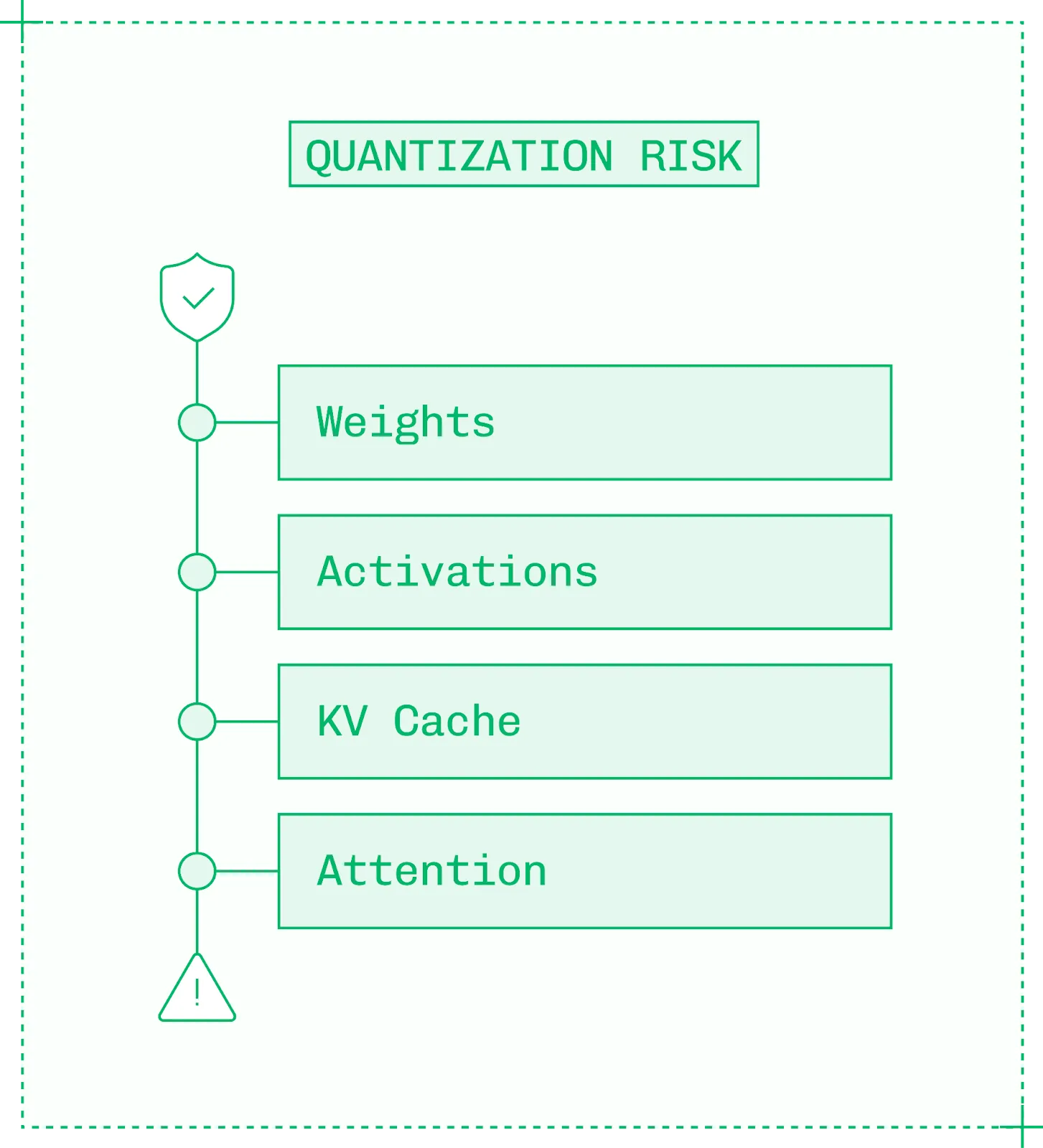 가중치와 활성화에 대한 양자화 위험은 낮고, KV 캐시는 보통, 어텐션은 높음
가중치와 활성화에 대한 양자화 위험은 낮고, KV 캐시는 보통, 어텐션은 높음
저정밀도 추론에 대한 중도적 접근 방식은 높은 다이나믹 레인지를 가진 FP8 과 같은 형식 (가능하다면 MXFP8 과 같은 마이크로 스케일링 형식) 을 사용하여 선별적인 선형 레이어, 활성화, 그리고 종 KV 캐시 값을 신중하게 양자화하는 것입니다. 이러한 높은 다이나믹 레인지 형식을 사용하더라도 어텐션 레이어의 구성 요소는 좀처럼 양자화되지 않습니다.
접근법 #2: 추론적 디코딩 (Speculative decoding)
LLM 추론의 디코드 단계는 토큰을 한 번에 하나씩 생성하는 자기회귀 (autoregressive) 프로세스입니다. 디코드의 병목 현상은 메모리 대역폭이며, 가중치가 메모리에서 읽히는 동안 저~중간 배치 크기에서 연산 장치가 유휴 상태로 남습니다.
추론적 디코딩 (Speculative decoding) 은 타겟 모델을 통해 순전파 (forward pass) 당 여러 개의 토큰을 생성해 보려고 그 남는 연산 능력을 활용합니다. 만일 추론 엔진이 메모리를 통한 가중치 왕복 (round-trip) 당 2 개, 3 개, 혹은 그 이상의 토큰을 생성할 수 있다면, 초당 훨씬 더 많은 토큰을 생성할 수 있을 것입니다.
참고로 추론적 디코딩은 TTFT(첫 번째 토큰까지의 시간) 가 아닌 TPS/ITL(토큰 간 지연 시간) 만 개선합니다.
추론적 디코딩에는 여러 알고리즘이 있으며 공통된 메커니즘을 공유합니다.
- 추론기 (speculator) 가 하나 이상의 초안 토큰 (draft tokens)을 생성합니다.
- 타겟 모델(가속화하려는 기본 모델) 이 이 토큰들이 모델이 생성할 토큰과 일치하는지 확인하기 위한 검증 (validation)을 수행합니다.
- 타겟 모델은 유효한 모든 초안 토큰을 수용하고 자체적으로 추가 토큰을 하나 생성하여 순전파를 완료합니다.
이는 순전파 (또는 디코드 루프의 반복) 당 N+1 개의 토큰을 생성하며, 여기서 N 은 수용된 초안 토큰의 수입니다.
초안 토큰 생성은 공짜가 아닙니다. 연산과 메모리가 모두 소요됩니다. 하지만 타겟 모델이 초안 토큰을 검증하는 것은 오리지널 토큰을 생성하는 것보다 훨씬 빠릅니다. 스도쿠 퍼즐을 예로 들면, 푸는 것은 어렵지만 정답이 맞는지 확인하는 것은 매우 쉽습니다. 타겟 모델에게 토큰 생성은 스도쿠를 푸는 것과 같고, 초안 토큰 검증은 완성된 스도쿠를 확인하는 것과 같습니다.
어떤 추론적 디코딩 전략이든 성능 향상은 다음 세 가지 요인에 달려 있습니다.
- 초안 토큰 비용: 초안 토큰을 생성하는 데 걸리는 시간입니다.
- 초안 시퀀스 길이: 순전파 당 생성된 초안 토큰 수입니다.
- 토큰 수용률: 타겟 모델에 의해 수용된 초안 토큰의 비율입니다.
토큰 수용률은 초안 시퀀스 초반에는 높지만, 시퀀스가 깊어질수록 초안 토큰의 신뢰도는 떨어집니다.
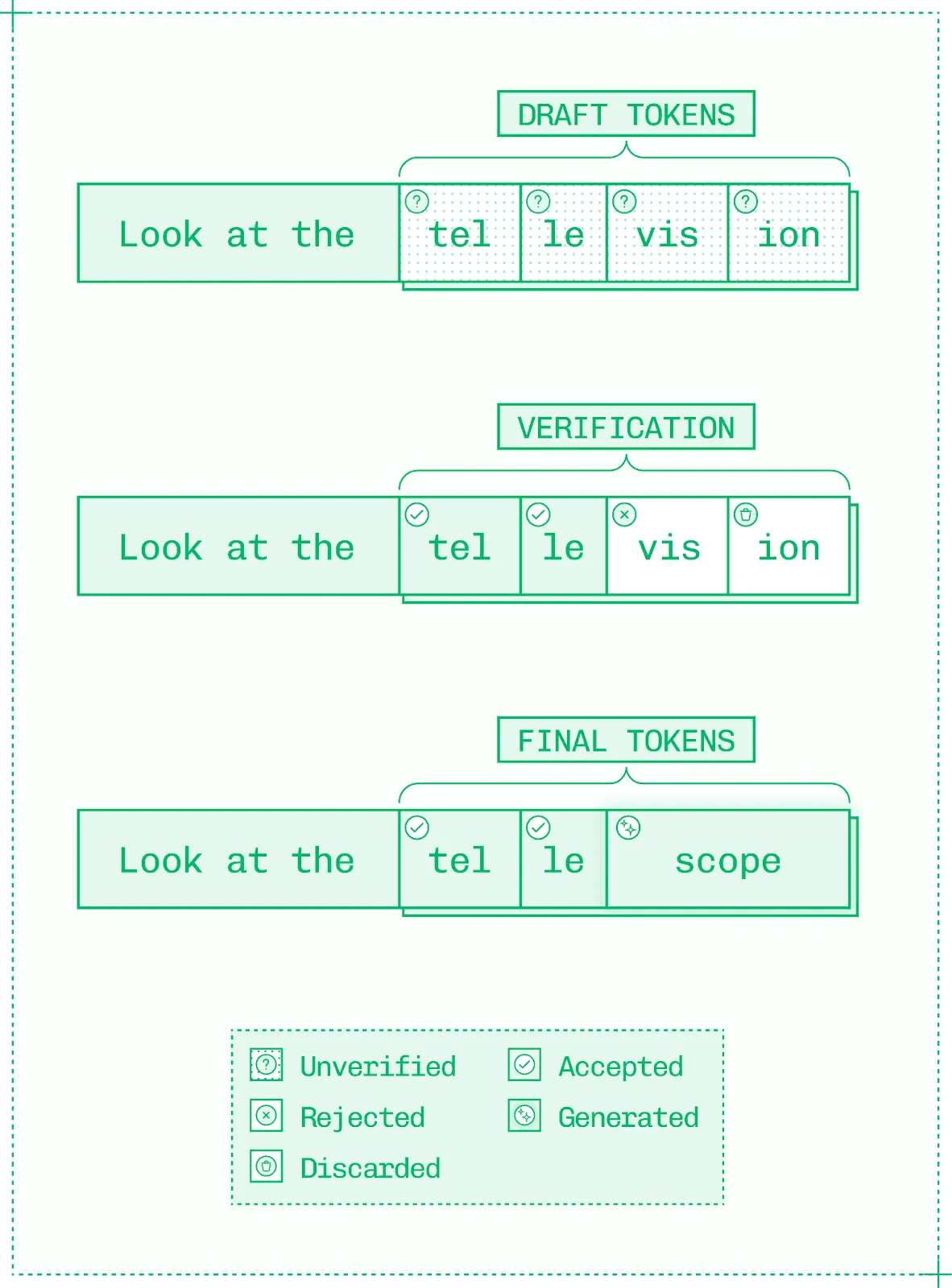 초안 토큰 생성 및 검증부터 후속 토큰 생성을 위한 접두사 수용까지의 추론적 디코딩
초안 토큰 생성 및 검증부터 후속 토큰 생성을 위한 접두사 수용까지의 추론적 디코딩
짧고 높은 확률의 시퀀스를 목표로 삼아야 합니다. 토큰 생성 및 검증은 오리지널 모델에서 토큰을 생성하는 것에 비해 비용이 낮지만, 여전히 상당한 오버헤드가 따르기 때문입니다. 또한 한 번의 초안 토큰이 틀렸다고 기각되면, 시퀀스의 이후 토큰들도 모두 기각됩니다.
추론 (speculation) 작업은 토큰 수용률에 영향을 미치는 요소가 워낙 많아서 흥미롭습니다. 가장 큰 요소는 온도 (temperature) 파라미터입니다. 온도가 높을수록 예측하기 어려운 토큰 분포가 되어 추론적 디코딩의 효과가 줄어듭니다. 하지만 추론에 사용된 초안 모델이나 추가 디코더 헤드가 가령 역사보다 수학에 더 정통하다면, 수학이나 역사 같은 주제와 같은 단순한 요소조차 수용률에 차이를 만듭니다.
추론적 디코딩의 또 다른 제한점은 여유 연산 주기가 있는 저배치 크기에서 가장 유용하다는 점입니다. 더 높은 배치 크기에서는 연산이 너무 포화되어 검증을 감당할 수 없으므로 추론적 디코딩을 동적으로 비활성화해야 합니다. 각 추론 알고리즘은 이러한 절충 관계를 각기 다르게 처리하며, 상황에 맞는 올바른 알고리즘을 신중하게 구현하면 TPS 에서 커다란 개선을 이끌 수 있습니다.
접근법 #3: 캐싱 (Caching)
사전 채움 (prefill) 단계에서 추론 엔진은 입력 시퀀스에 대한 KV 캐시 (각 토큰의 키와 값 저장소) 를 구축합니다. 그리고 디코드 단계에서 각 토큰마다 KV 캐시를 갱신합니다. 추론이 자기회귀적이므로, 각 새 토큰의 값은 시퀀스의 모든 이전 토큰 값에 의존합니다.
모든 추론 엔진은 기본적으로 요청 단위로 KV 캐싱을 사용합니다. KV 캐싱이 없다면, 후속 토큰마다 시퀀스 전체의 모든 이전 값을 다시 계산해야 하므로 LLM 추론은 극도로 느려질 것입니다.
하지만 엔지니어들은 각 추론 시퀀스 내에서만 사용하는 대신 요청 간에 KV 캐시를 재사용하여 더 큰 효용을 얻을 수 있습니다. 다음 두 개의 프롬프트를 보십시오. 대부분의 토크나이저 기준으로 각각 4 개의 토큰을 가집니다.
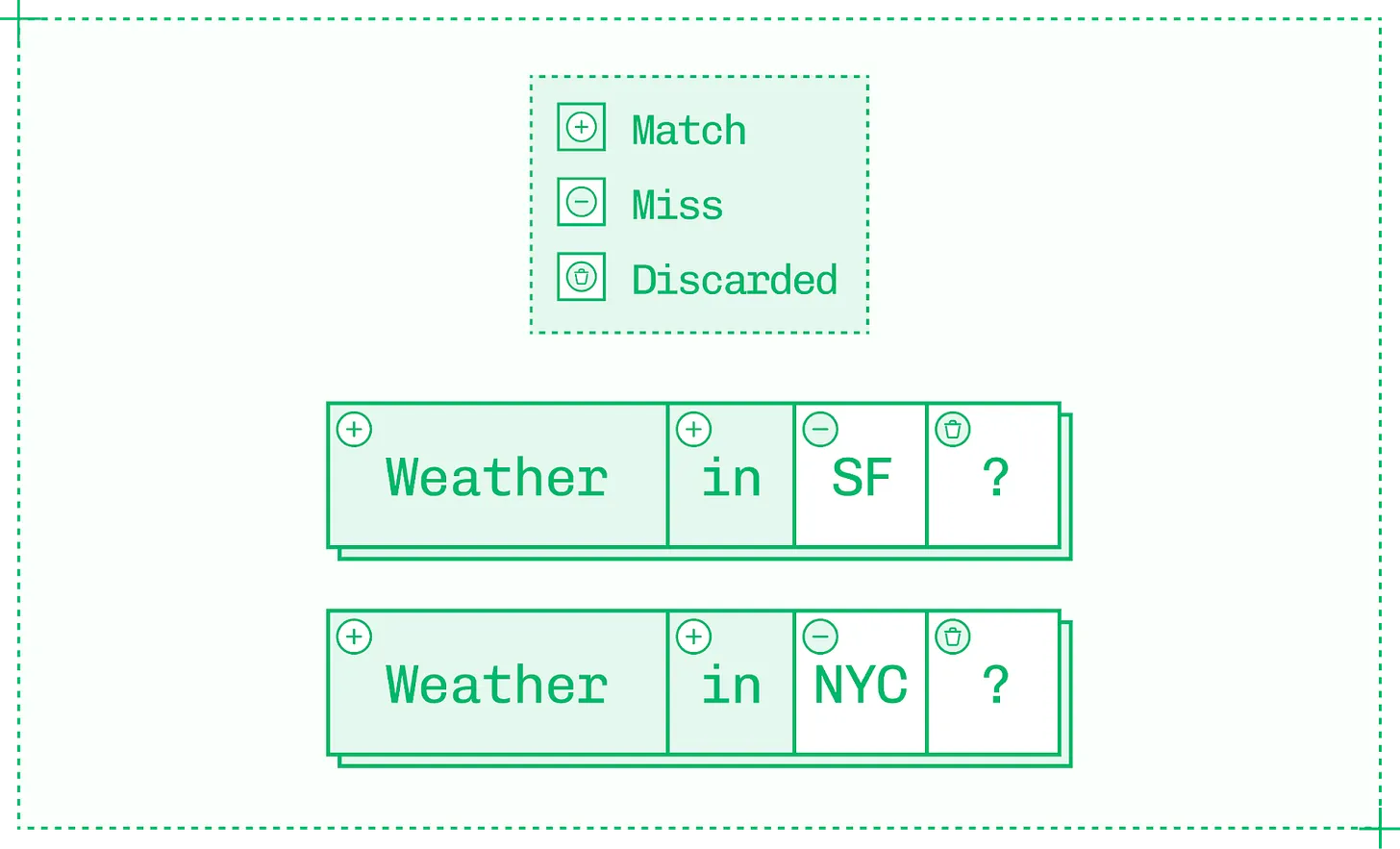 2 토큰 접두사가 일치하는 4 토큰 시퀀스 쌍
2 토큰 접두사가 일치하는 4 토큰 시퀀스 쌍
기본적으로 추론 엔진은 각 프롬프트의 4 개 토큰 전부에 대해 사전 채움을 실행해야 합니다. 하지만 각 프롬프트의 첫 번째 토큰들("Weather in")은 쌍 간의 공유 접두사를 형성합니다. 접두사 캐싱 (prefix caching) 을 사용하면 첫 번째 요청의 KV 캐시를 재사용하여 처음 두 토큰에 대한 사전 채움을 건너뛰고 기존 KV 캐시를 읽어오면, 두 번째 요청의 TTFT 를 개선할 수 있습니다.
토큰 종량제 API 가 "캐시 히트" 입력 토큰에 대해 "캐시 미스" 토큰보다 적게 청구하는 이유는 바로 이것입니다. 캐시된 토큰을 재사용하는 데는 연산 능력과 시간이 거의 들지 않기 때문입니다.
추론 엔지니어로서 귀사는 자체 배포에서 지연 시간을 줄이고 처리량을 개선하며 따라서 비용을 절감하기 위해 동일한 원칙을 적용할 수 있습니다. 토큰 2 개를 절약한다고 TTFT 에 큰 영향이 가지는 않지만, 접두사 캐싱은 특정 도메인에서 수천 개의 토큰에 대한 사전 채움을 건너뛸 수 있습니다.
- 복잡한 시스템 프롬프트: 에이전트, 고객용 챗봇, RAG 스캐폴드, 도구 호출은 대개 모든 호출에서 길고 복잡한 시스템 프롬프트를 특징으로 합니다.
- 코드 완성: 코드 완성, 코드 생성 및 기타 코딩 기능은 공유 컨텍스트로 수천 줄의 동일한 코드를 전달해야 합니다.
- 문서 및 검색: 문서 요약, 질의응답, 검색은 모두 사용자 프롬프트 앞에 반복되는 컨텍스트를 추가합니다.
- 멀티턴 대화: 일반적인 대화는 채팅 템플릿의 모든 메시지를 다시 반복하므로, 턴이 늘어날수록 접두사 캐싱으로 인한 절감 효과도 커집니다.
접두사 캐싱은 입력 시퀀스의 시작부터 첫 번째 반복되지 않는 토큰 직전까지 작동합니다. 날씨 예시의 네 번째 토큰인 물음표는 두 입력 시퀀스에서 공유됩니다. 하지만 접두사는 첫 번째 반복되지 않는 토큰에서 끝나므로, 네 번째 토큰은 캐시에서 읽히지 않습니다. 접두사는 첫 번째 고유 토큰에서 끝나므로, 귀사의 컨텍스트 엔지니어링이 TTFT 절감 효과를 결정합니다. 동일한 프롬프트에 대한 또 다른 접근 방식을 고려해 보십시오.
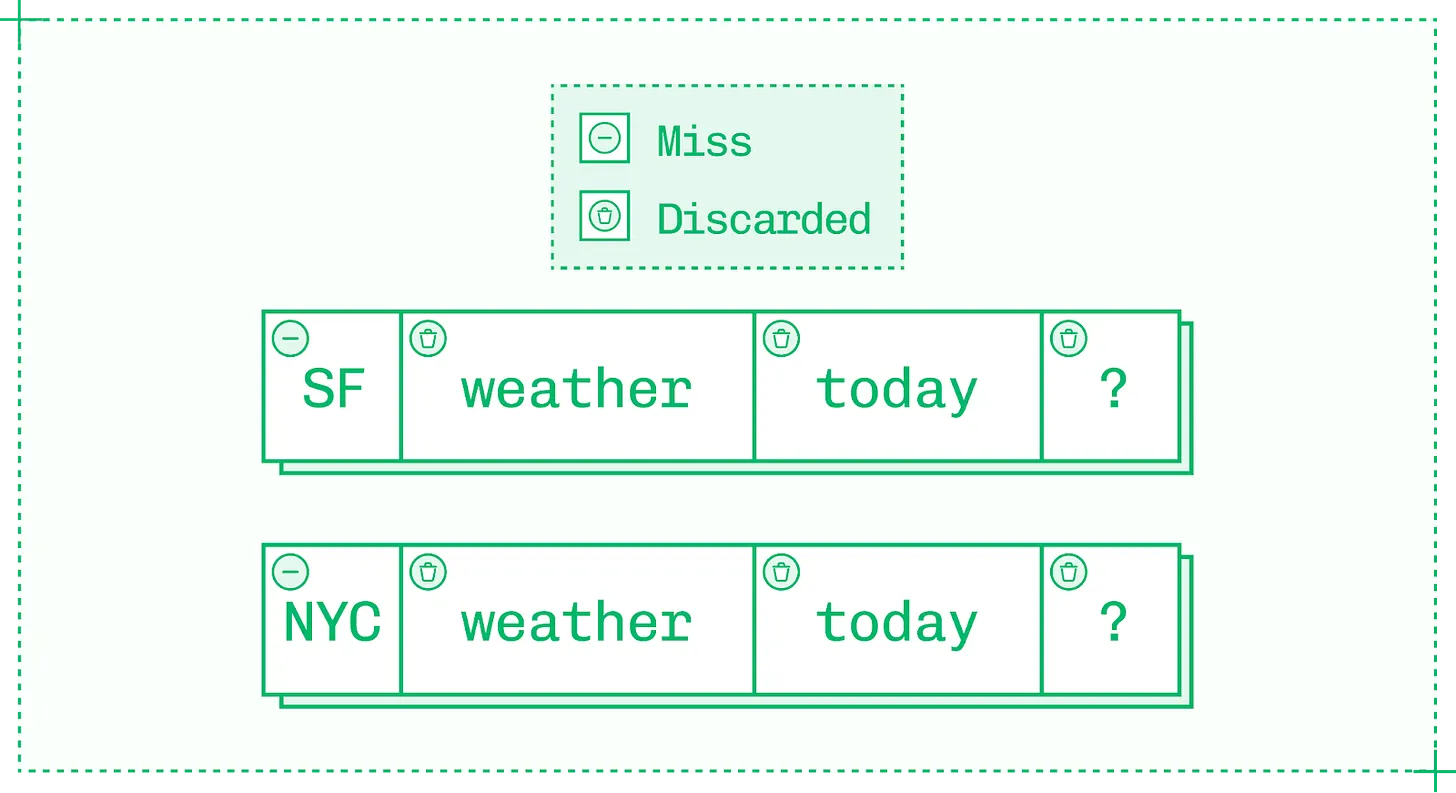 접두사 일치가 없는 4 토큰 시퀀스 쌍. 첫 토큰이 다르면 이후 3 개가 같아도 무의미
접두사 일치가 없는 4 토큰 시퀀스 쌍. 첫 토큰이 다르면 이후 3 개가 같아도 무의미
여기서는 두 시퀀스의 아주 첫 토큰이 다르므로, 이후 토큰이 모두 같더라도 접두사 캐싱으로 인한 절감 효과는 없습니다. 접두사 캐싱의 이점을 살리려면 새로운 (novel) 토큰이 프롬프트에서 가능한 한 뒤에 오도록 해야 합니다.
접근법 #4: 병렬화 (Parallelism)
다중 GPU 모델 추론의 기본 전략은 텐서 병렬화 (Tensor Parallelism, TP) 여야 합니다. 이는 라마 405B 와 같은 조밀 (dense) 모델과 현재 오픈 모델 지형을 지배하는 MoE(전문가 혼합) 모델을 모두 지원합니다.
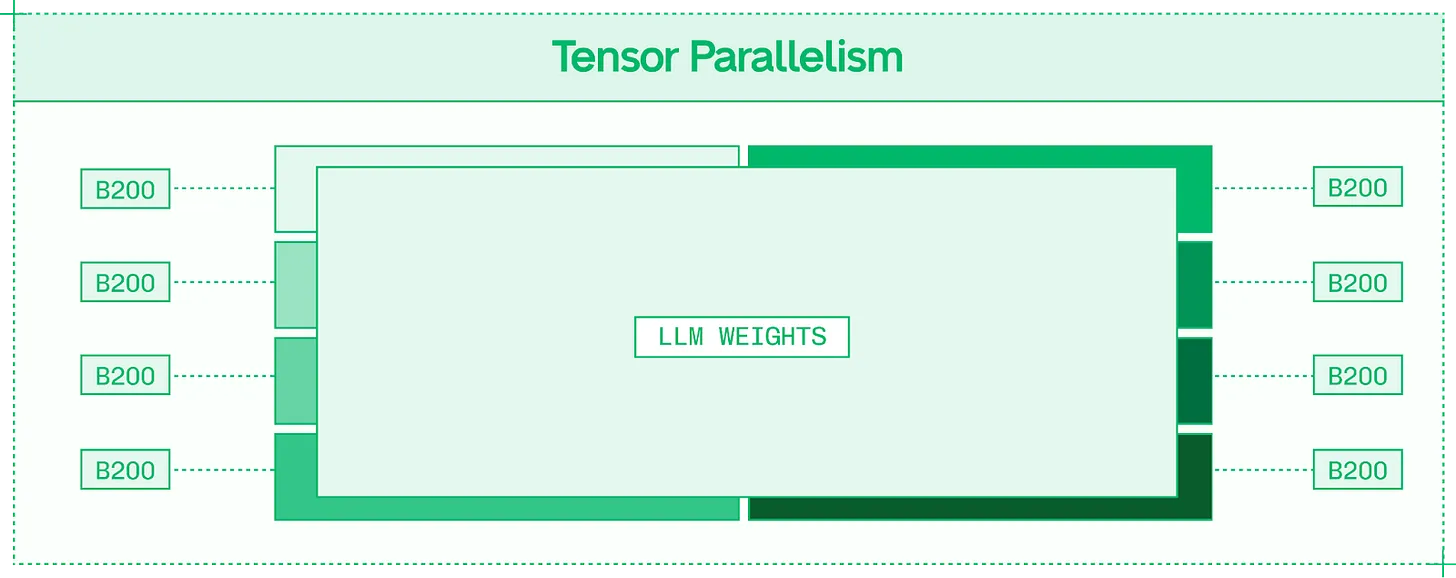 텐서 병렬화는 GPU 간 가중치를 분할하여 VRAM 리소스를 공유하여 대형 모델을 빠르게 실행
텐서 병렬화는 GPU 간 가중치를 분할하여 VRAM 리소스를 공유하여 대형 모델을 빠르게 실행
TP 는 (레이어를 온전하게 유지하는 파이프라인 병렬화와 대조적으로) 모델의 각 레이어를 분할하고 레이어 단편들을 할당된 GPU 에 분산하여 작동합니다. 각 레이어에 대해 가중치 메모리에서 읽고 행렬 곱셈을 실행하는 비용이 GPU 간에 분산됩니다.
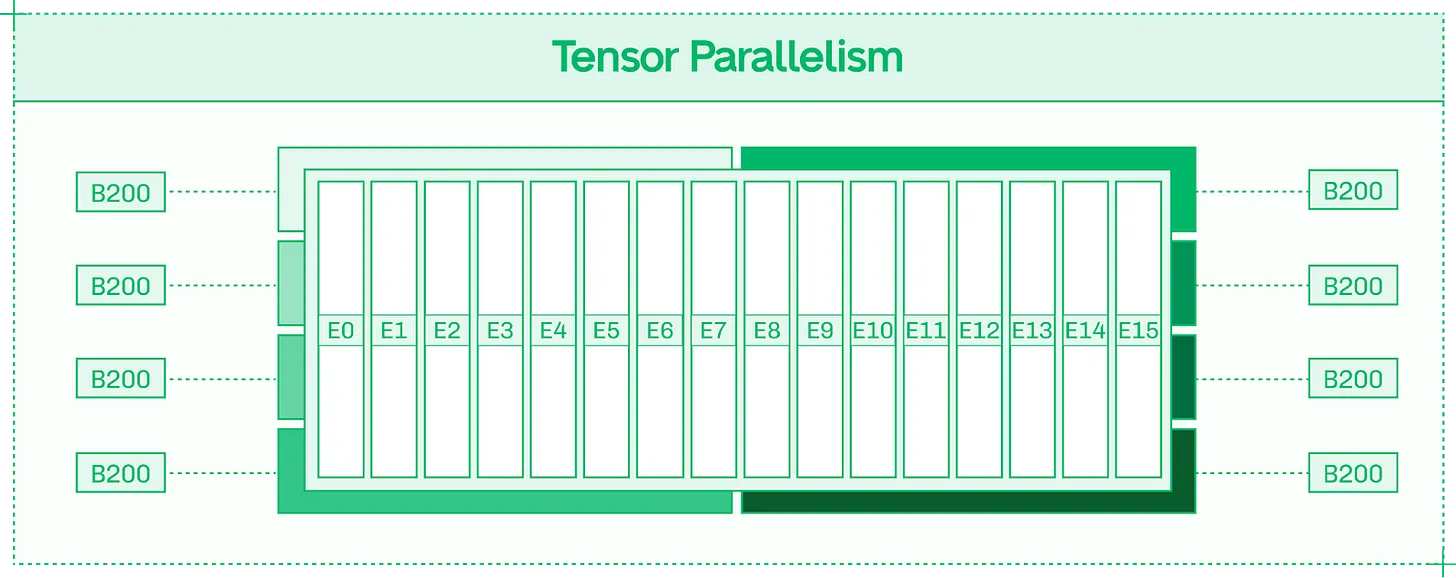 MoE 모델의 경우 각 전문가는 텐서 병렬화로 여러 GPU 에서 실행
MoE 모델의 경우 각 전문가는 텐서 병렬화로 여러 GPU 에서 실행
하지만 다음 레이어를 계산하기 전에 각 레이어의 결과는 올 리듀스 (all-reduce) 방식 (8 개 GPU 전체에서) 으로 단일 출력으로 통신되어야 합니다. 고대역폭 노드 내 NVLink 및 NVSwitch 가 있는 노드에서는 이 통신 오버헤드가 최소화됩니다.
모델이 충분히 크고 시퀀스가 충분히 길어 통신 오버헤드가 더 빠른 순전파보다 무겁지 않다면 (대부분의 최첨단 모델이 이에 해당), 텐서 병렬화를 늘리면 사용자당 TPS 가 향상됩니다.
전문가 병렬화 (Expert Parallelism, EP) 는 8 개 GPU 에서 EP8 로 서빙되는 128 개 전문가 모델의 경우처럼 GPU 간에 전문가들을 깔끔하게 나눕니다. 이 경우 각 GPU 는 16 개의 완전한 전문가를 호스팅합니다.
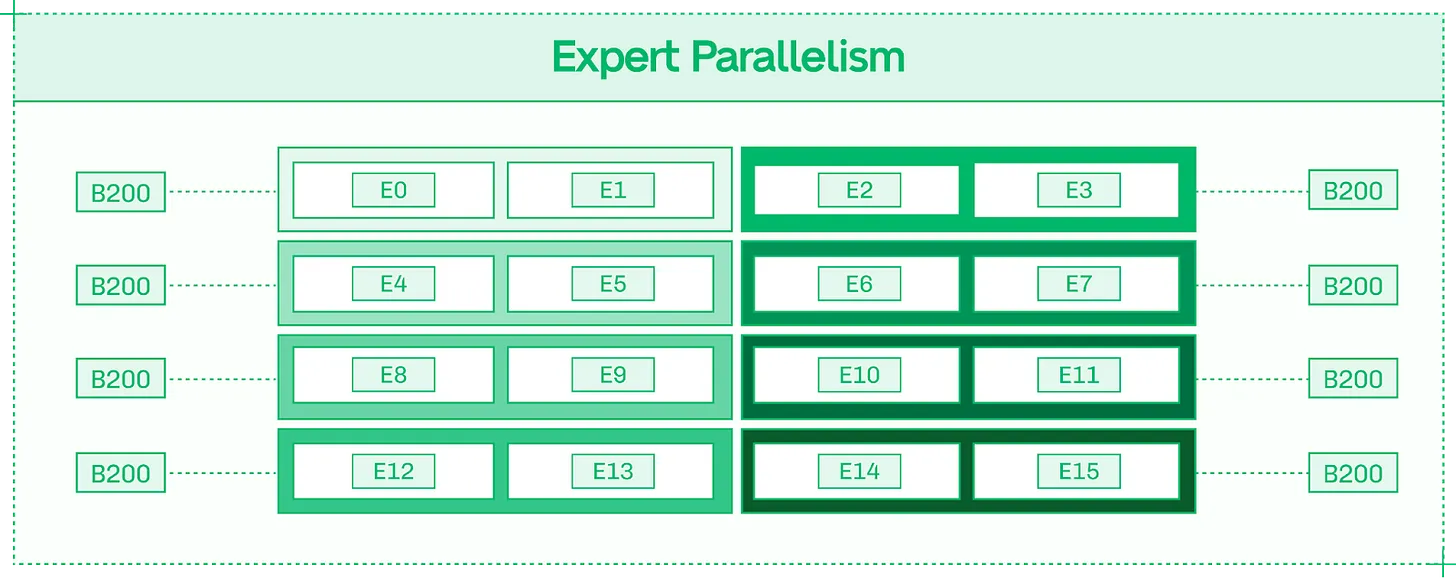 EP 는 단일 GPU 내에서 각 전문가를 실행하며, 각 GPU 는 여러 전문가를 호스팅
EP 는 단일 GPU 내에서 각 전문가를 실행하며, 각 GPU 는 여러 전문가를 호스팅
EP 는 전체 시스템 처리량을 개선하여 추론을 더 확장 가능하고 저렴하게 만듭니다. 개별 전문가들이 토큰을 별도로 처리하므로 각 토큰은 똑같은 시간이 걸리지만, 시스템 전체는 더 많은 동시 토큰을 처리할 수 있습니다.
많은 배포에서 이 두 이점을 모두 얻기 위해 TP 와 EP 를 혼용합니다.
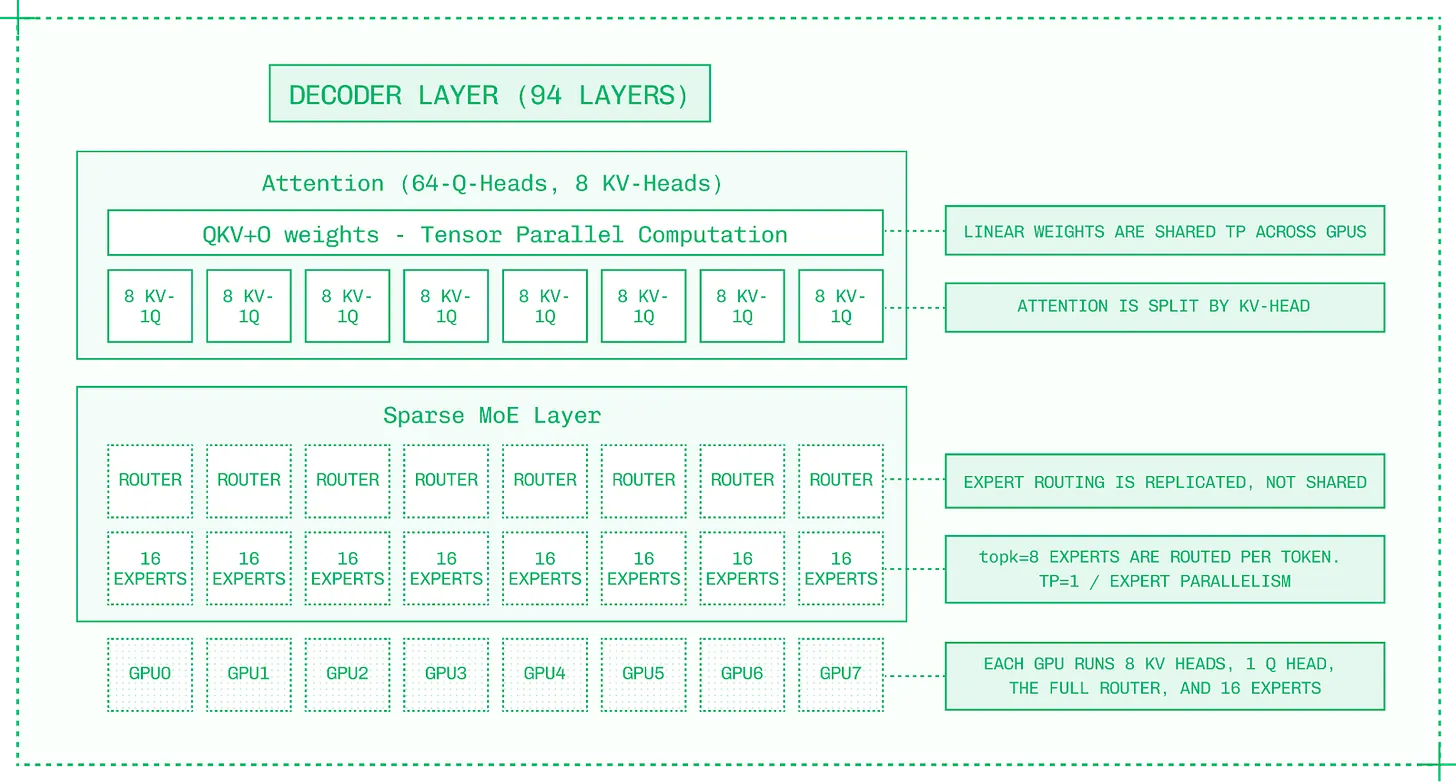 이 배포는 어텐션에는 TP 를, 희박한 MoE 레이어에는 EP 를 사용
이 배포는 어텐션에는 TP 를, 희박한 MoE 레이어에는 EP 를 사용
EP 는 텐서 병렬화보다 GPU 간 통신가 적게 필요합니다. 각 토큰이 어떤 전문가를 활성화할지 결정하는 전문가 라우터 (Expert Router) 는 모델의 비교적 작은 구성 요소이므로 각 GPU 에 복제됩니다. 전문가 간에 토큰을 전달하려면 GPU 간 통신이 필요하지만, TP 와 달리 각 레이어의 결과를 수집할 필요는 없습니다. 이러한 낮은 통신 오버헤드 덕분에 EP 는 멀티 노드 배포와 상호 연결 대역폭이 제한된 시스템에서도 확장이 잘 됩니다.
접근법 #5: 분리 (Disaggregation)
분리 (Disaggregation) 는 추론 엔지니어링의 세 가지 중요한 아이디어를 결합합니다.
- 사전 채움 (prefill) 은 첫 번째 토큰 시점 (TTFT) 을 결정하는 연산 집약적 (compute-bound) 프로세스인 반면, 디코드는 TPS 를 결정하는 메모리 집약적 (memory-bound) 프로세스입니다.
- 특화 (Specialization) 는 커널 선택에서 추론 엔진 파라미터 튜닝에 이르기까지 모든 것의 성능을 향상시킵니다.
- 저대역폭 상호 연결의 병목 현상을 피할 수 있다면, 모델 서빙을 여러 GPU 나 심지어 여러 노드에서 효과적으로 병렬화할 수 있습니다.
트래픽이 많을 때 사전 채움과 디코드가 동일한 노드에서 실행되면 서로를 방해할 가능성이 더 높습니다. 이상적으로 사전 채움은 더 많은 연산 리소스를, 디코드는 더 많은 메모리를 사용하며 두 과정이 효율적으로 공존해야 합니다. 하지만 더 큰 배치와 더 많은 연산 집약적 최적화로 인해 사전 채움와 디코드가 리소스를 놓고 경쟁하기 시작합니다.
분리 (disaggregation), 또는 분리형 서빙 (disaggregated serving) 은 사전 채움과 디코드를 별도의 GPU 나 노드의 별도 엔진으로 분리한다는 발상입니다.
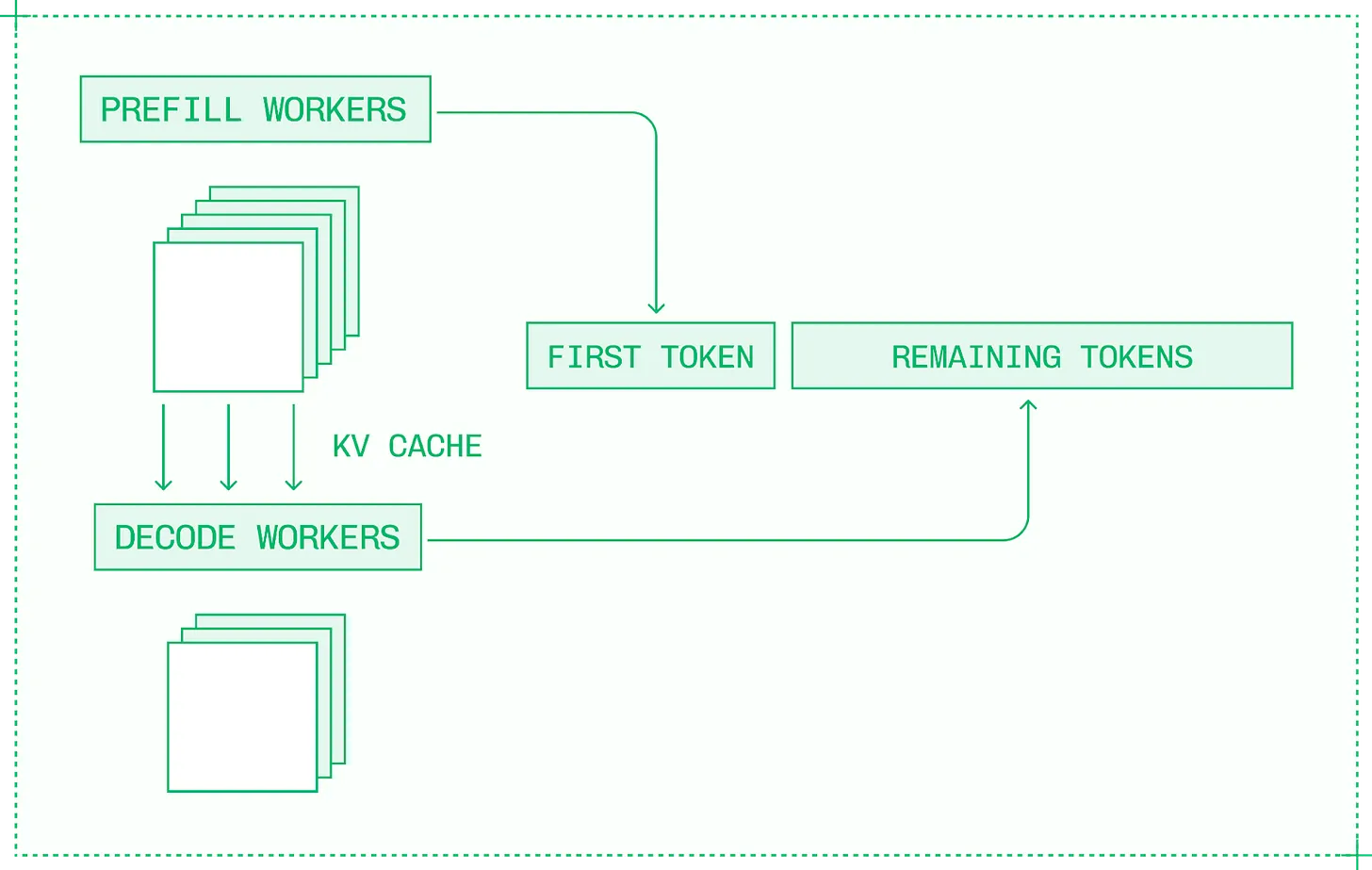 분리는 첫 번째 토큰 생성을 위한 사전 채움 워커와 후속 토큰 생성을 위한 디코드 워커를 할당
분리는 첫 번째 토큰 생성을 위한 사전 채움 워커와 후속 토큰 생성을 위한 디코드 워커를 할당
분리는 LLM 추론을 3 단계 프로세스로 바꿉니다.
- 사전 채움 엔진이 입력 시퀀스를 받아 KV 캐시를 생성하면서 첫 번째 토큰을 계산합니다.
- 사전 채움 엔진이 하드웨어 상호 연결을 통해 KV 캐시를 디코드 엔진으로 전송합니다.
- 디코드 엔진이 이후의 모든 토큰을 계산합니다.
조건부 분리 (conditional disaggregation) 에서는 요청이 먼저 디코드 엔진으로 전송되어 입력 시퀀스가 이미 캐시되었거나 로컬에서 처리할 만큼 짧은지 확인합니다.
- 그렇다면 디코드 엔진이 분리를 건너뛰고 로컬에서 사전 채움을 처리합니다.
- 아니라면 디코드 엔진이 분리형 서빙을 위해 요청을 사전 채움 엔진으로 전송합니다.
조건부 분리는 실제 트래픽에 더 적합합니다.
분리의 또 다른 이점은 별도의 사전 채움 엔진과 디코드 엔진을 사용하면 각 엔진을 개별적으로 최적화할 수 있고 시스템 전체도 최적화할 수 있다는 점입니다. 예를 들어 연산 집약적인 사전 채움 엔진은 메모리 집약적인 디코드 엔진보다 더 낮은 TP(텐서 병렬화) 가 필요합니다.
요약
여기서부터는 다시 게르겔리입니다.
추론 엔지니어링에 대한 이 심층 분석을 제공해 주신 필립 에게 감사드립니다. 이는 그의 신간 『인퍼런스 엔지니어링 (Inference Engineering)』전체 내용의 약 10% 에 해당합니다. 이 주제를 더 깊이 파고들고 싶다면 전체 책을 무료로 다운로드할 수 있습니다.
이 책은 단행본 (인쇄본) 으로도 출시될 예정입니다. 대기 명단에 가입하시면 출시 시점을 알려드립니다.
추론 엔지니어링이 더 이상 소수 선도 AI 연구소들의 "독점" 영역이 아니라는 점은 고무적입니다. OpenAI 나 앤트로픽 (Anthropic) 과 같은 주요 AI 모델 제작사들은 훈련부터 추론에 이르기까지 자사 AI 모델의 모든 측면을 통제하므로, 이들과는 추론 엔지니어링을 할 여지가 없습니다. 하지만 점점 더 유능해지는 오픈 모델 덕에 엔지니어링 팀는 모델 사용 방식을 다듬을 기회를 얻었으며, 이때 추론 엔지니어링의 이론과 실천이 귀중해집니다.
그럼에도 불구하고 추론 엔지니어링이라는 학문은 여전히 일부 기술 기업에게만 의미가 있어 보입니다. 추론 엔지니어링에 대한 투자를 정당화하려면 벤더들에게 추론 비용으로 큰돈을 지출하고 있어야 합니다. 바로 이 시점에서 오픈 모델 위에 자체 추론 스택을 구축하고 기존 사용량의 일부를 대체할 수 있는지 확인하기 위해 시간과 돈을 투자할 가치가 생깁니다.
추론 엔지니어링가 AI 버전의 "구축 (build) 대 구매 (buy)"의 딜레마는 아닐지 궁금합니다. SaaS(서비스형 소프트웨어) 의 경우 모든 기업은 이를 사내에서 구축할지, 벤더로부터 구매할지 결정해야 합니다. 예를 들어 프로젝트 관리 소프트웨어를 직접 구축할까요 (물론 가능합니다), 아니면 기존 제품을 살까요? 기능 플래그 (feature flag) 는 어떻고, 가시성 (observability) 은 또 어떻습니까?
숙련된 엔지니어들이라면 직접 구축하는 것 (시간과 지속적인 유지보수 부담) 의 장단점을 모두 이해합니다. 자체 LLM 스택을 튜닝하고 운영하는 것은 훨씬 더 새로운 분야이며, 추론 엔지니어링은 오픈 모델의 "기본 (out of the box)"제공 기능보다 더 나은 추론 스택을 구축하는 핵심에 있습니다.
추론 엔지니어링의 기초를 익히는 것은 가치 있는 기술처럼 느껴지며, 동시에 새롭고 흥미롭습니다. 추론 엔지니어링에 정통해지면 LLM 사용에 있어 귀 팀과 회사에 선택지를 만들어 줄 수 있습니다. 오픈 모델 위에서 자체 추론 스택을 실행하면 실행 내용과 가격 결정을 통제할 수 있습니다. 추론 엔지니어링은 위에서 소개한 필립의 책 발췌본의 기법들을 활용해 오픈 모델로부터 더 나은 성능을 달성할 수 있는 옵션을 만드는 데 도움을 줍니다.